Using R
Workflow and File Management
Here’s a quick workflow for starting a new project, which incorporates the key ideas of Reproducible Research:
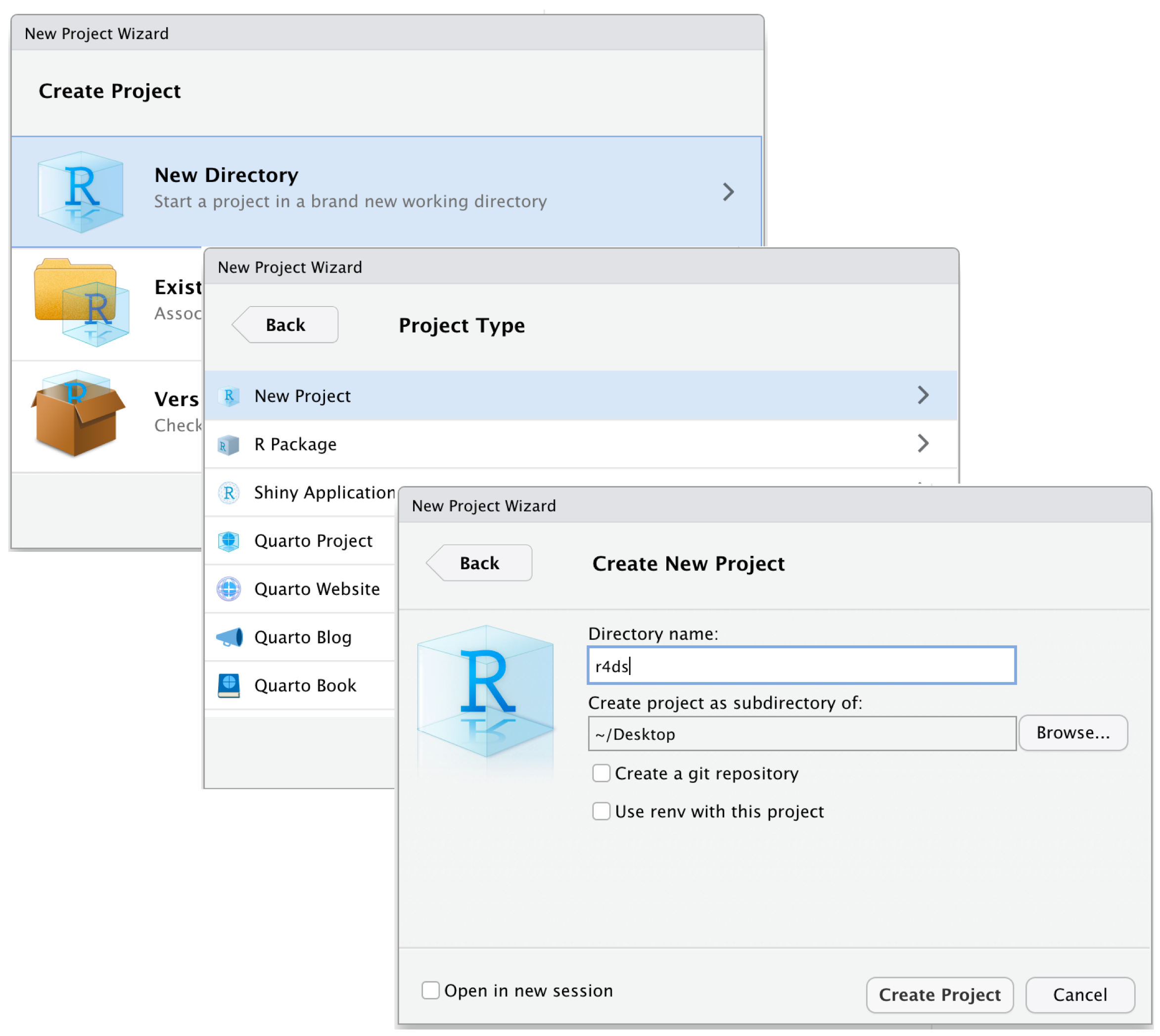
- Open Rstudio and create a new Rstudio Project by clicking
File > New Project. Name itpeco-4980-thesis.
Check if now your RStudio Window shows the project name on top right corner. If not, go to folder and double-click the
.RProjfile.Download the
000-setup.Rfrom here. Paste the000-setup.Rfile in the main project folder. Open it in the same Rstudio window with the project and run the complete file. Your folder structure is created.Copy your raw data in
Data/Rawfolder. Similarly, your scripts if any, inScripts/RScriptsfolder.Start your new
.qmdfile and save it in the main folder. Quarto is an in-built statistical programming and typesetting tool in R. The files are saved as.qmdfiles.
There are three building blocks in a .qmd file:

Use
here()package extensively in both, scripts and quarto file, when loading or saving the data. The example below in variable creation and merging section illustrates its usage.You can always zip the whole project folder for sharing. The receiver will just need to unzip and run the code after starting the associated
.RProjfile, without changing file paths on their computer.
Variable Creation and Merging Datasets
Close the RStudio Window. Download the dataset for practice exercise from here. Unzip if needed and then paste the dataset inside
../Data/Raw/.Click on the
.RProjfile in the folder you just created.Open a new
.qmdfile. Save it (ctrl/cmd + s) aspractice.qmdin the root/main folder of the project.Cope and paste the following code by creating a new R chunk in the
qmdfile. You can start a newRcode chunk by pressingcmd + option + Iorctrl + alt + I.
```{r}
install.packages("here")
library(here)
# See the output for each of the following lines | Use your own datasets
here()
# Make modification here after copying your dataset to this folder
here("Data","Raw","practice-datasets","V-Dem-CY-Full+Others-v12.rds")
# syntax is
# here("First subfolder from the root folder", "second subfolder",...., "file")
vdem_new <- readRDS(here("Data","Raw","practice-datasets","V-Dem-CY-Full+Others-v12.rds"))
```- Load the other datasets (in
simultated-datasetsfolder) by modifying the syntax above and storing it in objectseconomic_data_2000_2020andeconomic_data_1995_2024. Note how you have to change file paths as well as use different functions to load different file types (here dta and rds)
```{r}
install.packages("readstata13") # Package for loading stata files in R
install.packages("tidyverse") # Package for data wrangling
library(tidyverse)
library(readstata13)
economic_data_2000_2020 <- read_csv(here("Data/Raw/practice-datasets/simulated-datasets/Economic_Data_2000_2020.csv"))
economic_data_1995_2024 <- read.dta13(here("Data/Raw/practice-datasets/simulated-datasets/Economic_Data_1995_2024.dta"))
```- Inspect the datasets. There are multiple entries for each country corresponding to different years. Use the following code to merge and clean them.
```{r}
# Merge the datasets using a left join on 'country_code' and 'year'
merged_data <- left_join(economic_data_1995_2024,economic_data_2000_2020, by = c("country_code", "year"))
# Filter out rows with NA values in the GDP columns which indicate non-joined rows
filtered_data <- merged_data %>%
filter(!is.na(gdp.x) & !is.na(gdp.y))
# View the filtered data
print(filtered_data)
```- After merging create a new variable
gdp_pc
```{r}
# Assuming 'gdp.x' is the GDP from the first dataset and 'population' is the population variable
filtered_data <- filtered_data %>%
mutate(gdp_pc = ifelse(!is.na(gdp.x) & !is.na(population) & population > 0, gdp.x / population, NA))
# View the updated data with the new 'gdp_pc' column
print(filtered_data)
```- Save the new dataset inside your project folder.
```{r}
write_csv(filtered_data, file = here("Data/Clean/country-year-gdppc.csv"))
```- Save the file and close the project.