Code
dag_nomiss <- dagify(
Y ~ Y_l + R_Y,
Y_l ~ Age,
exposure = "Age",
outcome = "Y",
coords = list(
x = c(Age = 1, R_Y = 2, Y_l = 2, Y = 3),
y = c(Age = 0, R_Y = 1, Y_l = -1, Y = 0)
)
)
(mcar <- ggdag(dag_nomiss) + theme_dag())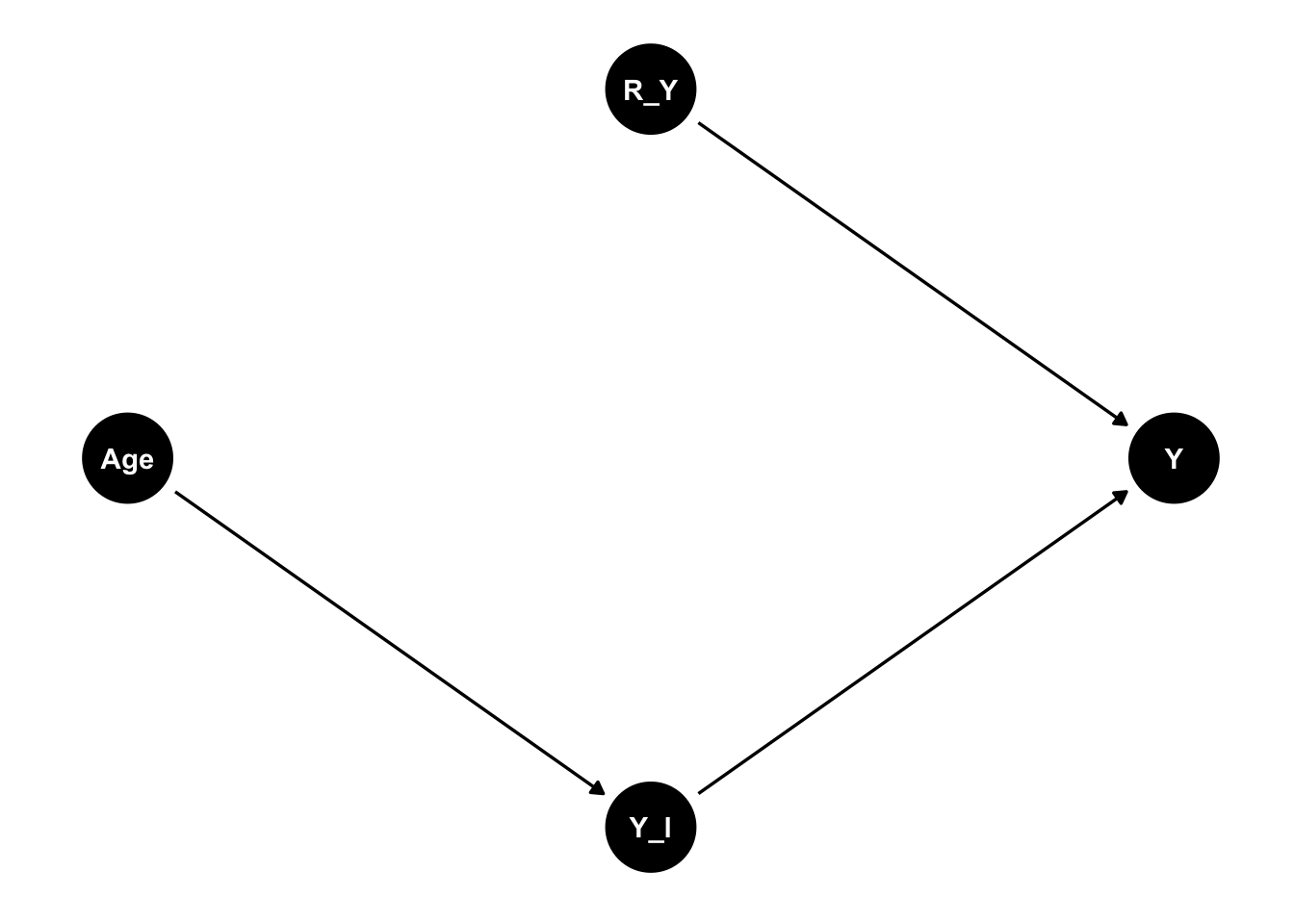

“When you lose something you can’t replace,
When you love someone, but it goes to waste,
Could it be worse?”
- Chris Martin, ruminating about dataset with missing data points in Fix You
Download the Lab folder from here.
Run the .RProj file.
Open 8003-missingdata-multipleimputations-10212024.qmd.
Mechanisms of Missingnness
Description of Missingness
Removal of Missingness
In data, missingness has been classified into three types based on the data generating mechanism leading to the occurrence of missingness (Rubin 1976, Little 2021). The following set-up explains them using DAGs.
Suppose there is an outcome of interest - Vote for Far-Right Candidate (\(Y\)). An explanatory variable of interest is \(Age\). An indicator variable (\(R_Y\)) captures the reporting of \(Y\), and \(Y_{Latent}\) is a latent variable which captures the intention to vote for far right candidate.
dag_nomiss <- dagify(
Y ~ Y_l + R_Y,
Y_l ~ Age,
exposure = "Age",
outcome = "Y",
coords = list(
x = c(Age = 1, R_Y = 2, Y_l = 2, Y = 3),
y = c(Age = 0, R_Y = 1, Y_l = -1, Y = 0)
)
)
(mcar <- ggdag(dag_nomiss) + theme_dag())
# MAR
dag_nomiss_1 <- dagify(
Y ~ Y_l + R_Y,
Y_l ~ Age,
R_Y ~ Age,
exposure = "Age",
outcome = "Y",
coords = list(
x = c(Age = 1, R_Y = 2, Y_l = 2, Y = 3),
y = c(Age = 0, R_Y = 1, Y_l = -1, Y = 0)
)
)
(mar <- ggdag(dag_nomiss_1) + theme_dag())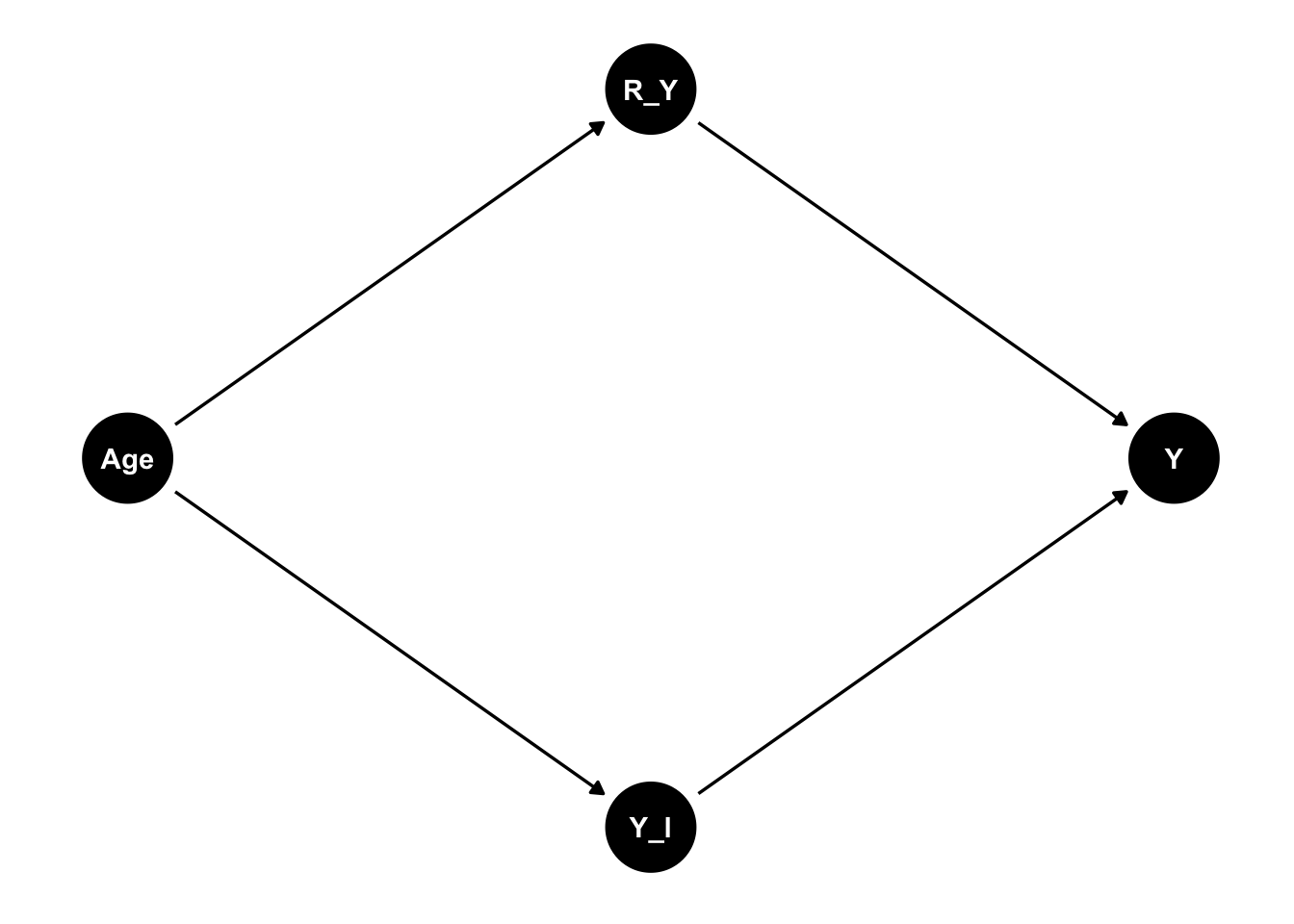
# NMAR
dag_nomiss_2 <- dagify(
Y ~ Y_l + R_Y,
Y_l ~ Age,
R_Y ~ Age,
R_Y ~ Y_l,
exposure = "Age",
outcome = "Y",
coords = list(
x = c(Age = 1, R_Y = 2, Y_l = 2, Y = 3),
y = c(Age = 0, R_Y = 1, Y_l = -1, Y = 0)
)
)
(nmar <- ggdag(dag_nomiss_2) + theme_dag())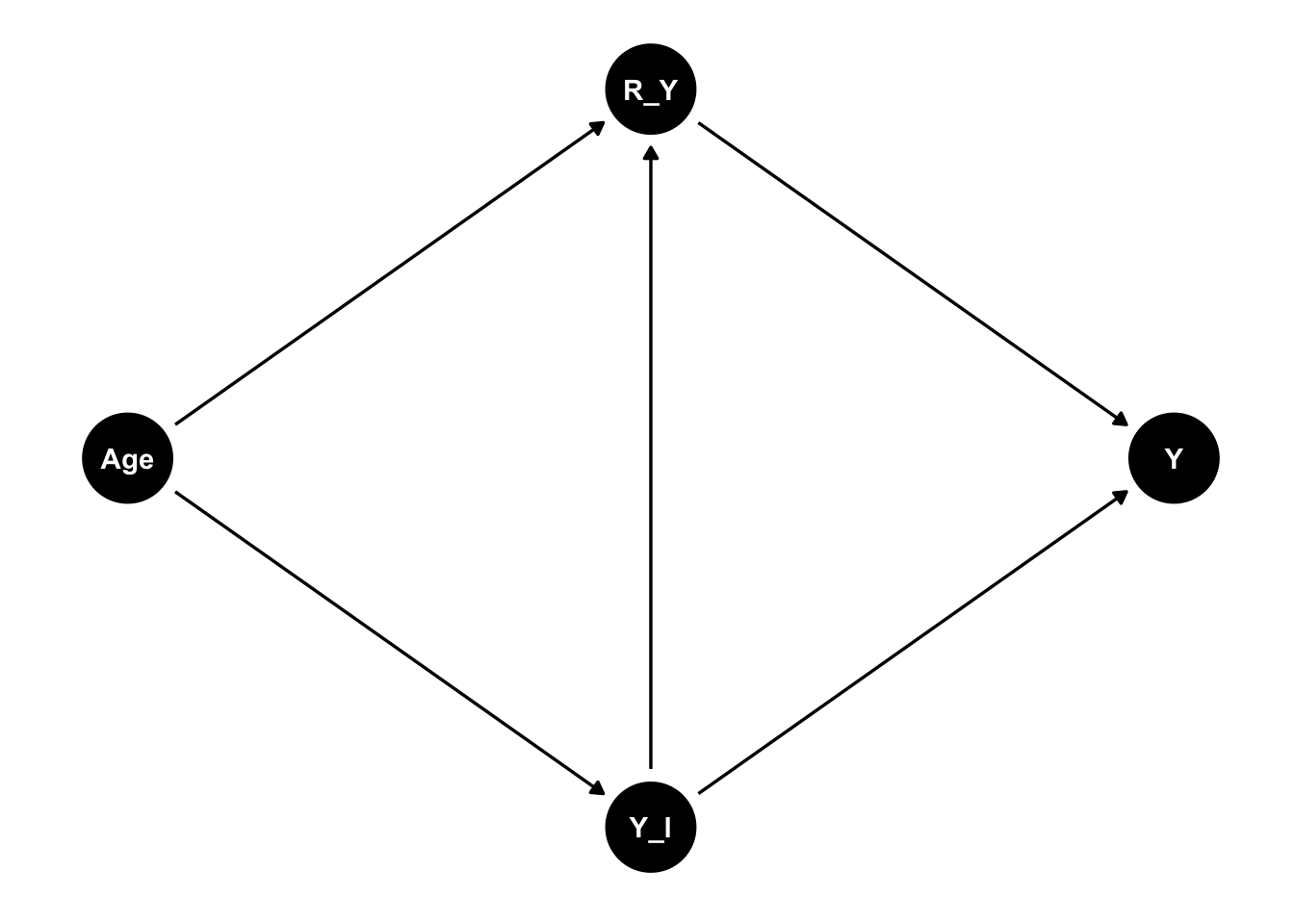
For this and the rest of the lab today we will use the paper and dataset used by Honaker, King, and Blackwell (2011) in their vignette for Amelia II
Milner, Helen V., and Keiko Kubota. 2005. “Why the Move to Free Trade? Democracy and Trade Policy in the Developing Countries.” International Organization 59 (1): 107–43. https://www.jstor.org/stable/3877880.
Rising international trade flows are a primary component of globalization. The liberalization of trade policy in many developing countries has helped foster the growth of these flows. Preceding and concurrent with this move to free trade, there has been a global movement toward democracy. We argue that these two trends are related: democratization of the political system reduces the ability of governments to use trade barriers as a strategy for building political support. Political leaders in labor-rich countries may prefer lower trade barriers as democracy increases. Empirical evidence supports our claim about the developing countries from 1970-99. Regime change toward democracy is associated with trade liberalization, controlling for many factors. Conventional explanations of economic reform, such as economic crises and external pressures, seem less salient. Democratization may have fostered globalization in this period.
Estimation
\[\begin{aligned} tradepolicy_{i,t} = \beta_0 & + \beta_1 REGIME_{i,t-1} + \beta_3 IMF_{i,t-1} \\ & + \beta_4OFFICE_{i,t-1} + \beta_5GDPPC_{i,t-1} \\ & + \beta_6LNPOP_{i,t-1} + \beta_7ECCRISIS_{i,t-1} \\ & + \beta_8BPCRISIS_{i,t-1} + \beta_9AVOPEN_{i,t-1} \\ & + u_i + \epsilon_{i,t} \end{aligned}\]
The following code is not needed for exercise today. I have written the Latex equation to given an example of how to write multi line equations in paper. Also note, there are dependencies on some Latex packages which some of which I add between lines 28-38 in the code above.
$$\begin{aligned}
tradepolicy_{i,t} = \beta_0 & + \beta_1 REGIME_{i,t-1} + \beta_3 IMF_{i,t-1} \\
& + \beta_4OFFICE_{i,t-1} + \beta_5GDPPC_{i,t-1} \\
& + \beta_6LNPOP_{i,t-1} + \beta_7ECCRISIS_{i,t-1} \\
& + \beta_8BPCRISIS_{i,t-1} + \beta_9AVOPEN_{i,t-1} \\
& + u_i + \epsilon_{i,t}
\end{aligned}$$In the example from Amelia page, a modified dataset is used
| Variable | Description |
|---|---|
year |
year |
country |
country |
tariff |
average tariff rates |
polity |
Polity IV Score[^polity] |
pop |
total population |
gdp.pc |
gross domestic product per capita |
intresmi |
gross international reserves |
signed |
dummy variable if signed an IMF agreement that year |
fivop |
measure of financial openness |
usheg |
measure of US hegemony[^hegemony] |
## library(Amelia) # Already loaded above, here just to remind
data("freetrade") # Modified dataset, included in the package# Seeing summary of all the variables
summary(freetrade) year country tariff polity
Min. :1981 Length:171 Min. : 7.10 Min. :-8.000
1st Qu.:1985 Class :character 1st Qu.: 16.30 1st Qu.:-2.000
Median :1990 Mode :character Median : 25.20 Median : 5.000
Mean :1990 Mean : 31.65 Mean : 2.905
3rd Qu.:1995 3rd Qu.: 40.80 3rd Qu.: 8.000
Max. :1999 Max. :100.00 Max. : 9.000
NA's :58 NA's :2
pop gdp.pc intresmi signed
Min. : 14105080 Min. : 149.5 Min. :0.9036 Min. :0.0000
1st Qu.: 19676715 1st Qu.: 420.1 1st Qu.:2.2231 1st Qu.:0.0000
Median : 52799040 Median : 814.3 Median :3.1815 Median :0.0000
Mean :149904501 Mean : 1867.3 Mean :3.3752 Mean :0.1548
3rd Qu.:120888400 3rd Qu.: 2462.9 3rd Qu.:4.4063 3rd Qu.:0.0000
Max. :997515200 Max. :12086.2 Max. :7.9346 Max. :1.0000
NA's :13 NA's :3
fiveop usheg
Min. :12.30 Min. :0.2558
1st Qu.:12.50 1st Qu.:0.2623
Median :12.60 Median :0.2756
Mean :12.74 Mean :0.2764
3rd Qu.:13.20 3rd Qu.:0.2887
Max. :13.20 Max. :0.3083
NA's :18 # Function to calculate missingness in a vector or data frame
mdesc <- function(df) {
# Check if the input is a vector
if (is.vector(df)) {
# Calculate the number of missing values in the vector
missing_col <- sum(is.na(df))
# Get the total number of elements in the vector
total_col <- length(df)
# Calculate the percentage of missing values
perc_missing_col <- missing_col / total_col
# Create a data frame summarizing the missingness statistics for the vector
out <- data.frame(
'missing' = missing_col, # Number of missing values
'total' = total_col, # Total number of elements
'percent_missing' = perc_missing_col # Percentage of missing values
)
# Return the result
return(out)
# Check if the input is a data frame
} else if (is.data.frame(df)) {
# Get the column names of the data frame (variables)
var_col <- colnames(df)
# Calculate the number of missing values for each column
missing_col <- unlist(lapply(df, function(x) sum(is.na(x))))
# Get the total number of rows in the data frame (same for all variables)
total_col <- nrow(df)
# Calculate the percentage of missing values for each column
perc_missing_col <- missing_col / total_col
# Create a data frame summarizing the missingness statistics for each variable
out <- data.frame(
'variable' = var_col, # Name of the variable (column)
'missing' = missing_col, # Number of missing values in the column
'total' = total_col, # Total number of rows in the data frame
'percent_missing' = perc_missing_col # Percentage of missing values
)
# Remove row names for cleaner output
rownames(out) <- NULL
# Return the result
return(out)
# If the input is neither a vector nor a data frame, return an error
} else {
stop('Please enter a vector or data.frame!')
}
}# Missingness on DV
mdesc(freetrade$tariff) missing total percent_missing
1 58 171 0.3391813# Missingness in whole dataset
mdesc(freetrade) variable missing total percent_missing
1 year 0 171 0.00000000
2 country 0 171 0.00000000
3 tariff 58 171 0.33918129
4 polity 2 171 0.01169591
5 pop 0 171 0.00000000
6 gdp.pc 0 171 0.00000000
7 intresmi 13 171 0.07602339
8 signed 3 171 0.01754386
9 fiveop 18 171 0.10526316
10 usheg 0 171 0.00000000VIM packageAggregation Plots
Aggregation plots provide a high-level overview of missingness int he dataset. Together the two plots below show missingness in the individual variables as well as joint-missingness in the data.
This code is using the aggr function to perform exploratory data analysis on the freetrade dataset. The numbers argument is set to TRUE, which means that the function will display the number of missing values for each variable in the dataset.
# install.packages("VIM")
# library(VIM)
mice_plot <- aggr(freetrade, col=c('skyblue','yellow'),
numbers=TRUE, sortVars=TRUE,prop = c(TRUE, FALSE),
labels=names(freetrade), cex.axis=.7,interactive = FALSE,
gap=3, ylab=c("Missing data","Pattern"))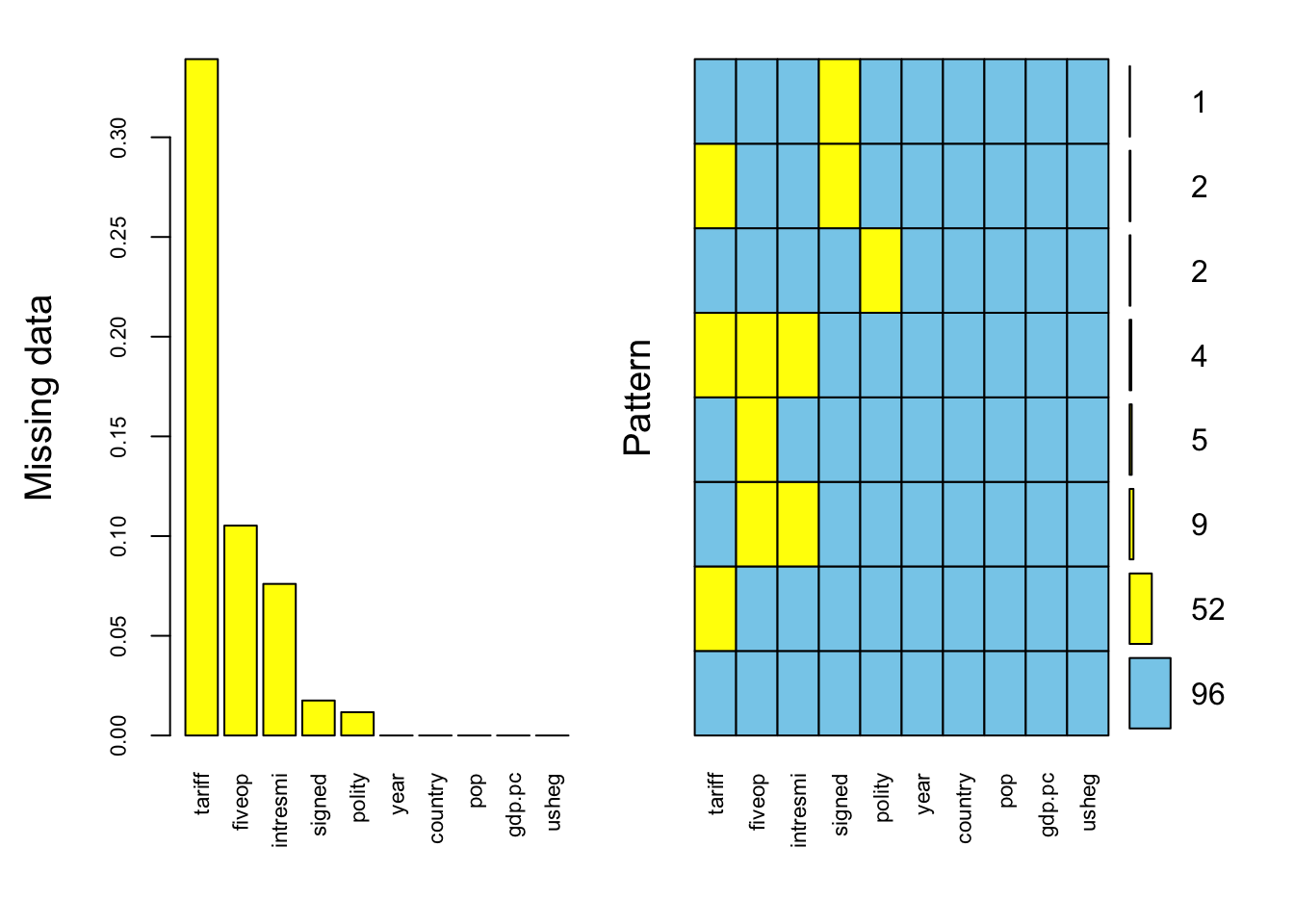
Variables sorted by number of missings:
Variable Count
tariff 0.33918129
fiveop 0.10526316
intresmi 0.07602339
signed 0.01754386
polity 0.01169591
year 0.00000000
country 0.00000000
pop 0.00000000
gdp.pc 0.00000000
usheg 0.00000000Spinogram and Spineplot
Spine plots from the VIM packages let’s us go deeper into invetigating missingness in the data between combination of any two variables. The utilities in ggmice package (covered in next section) performs similar task with different visual tools.
spineMiss(freetrade[, c("polity", "tariff")],interactive = FALSE)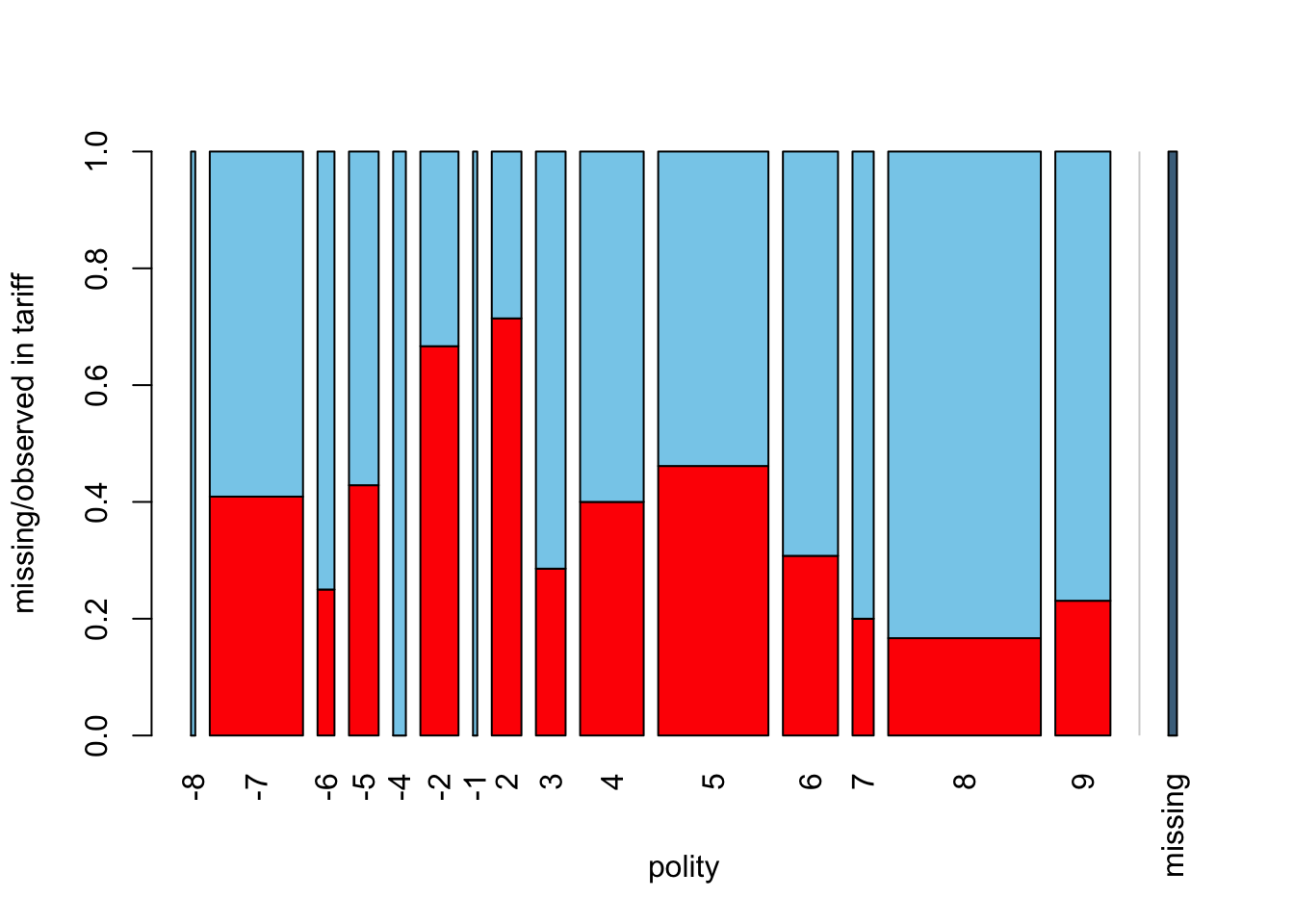
The relative width of the bars for different polity scores the frequency of this category in the dataset. Within each bar, the missing proportion of earnings is shown, while the shadowed bar on the right-hand side presents this proportion for the whole dataset.
Similarly, let’s try with variable fiveop.
spineMiss(freetrade[, c("fiveop", "tariff")],interactive = FALSE)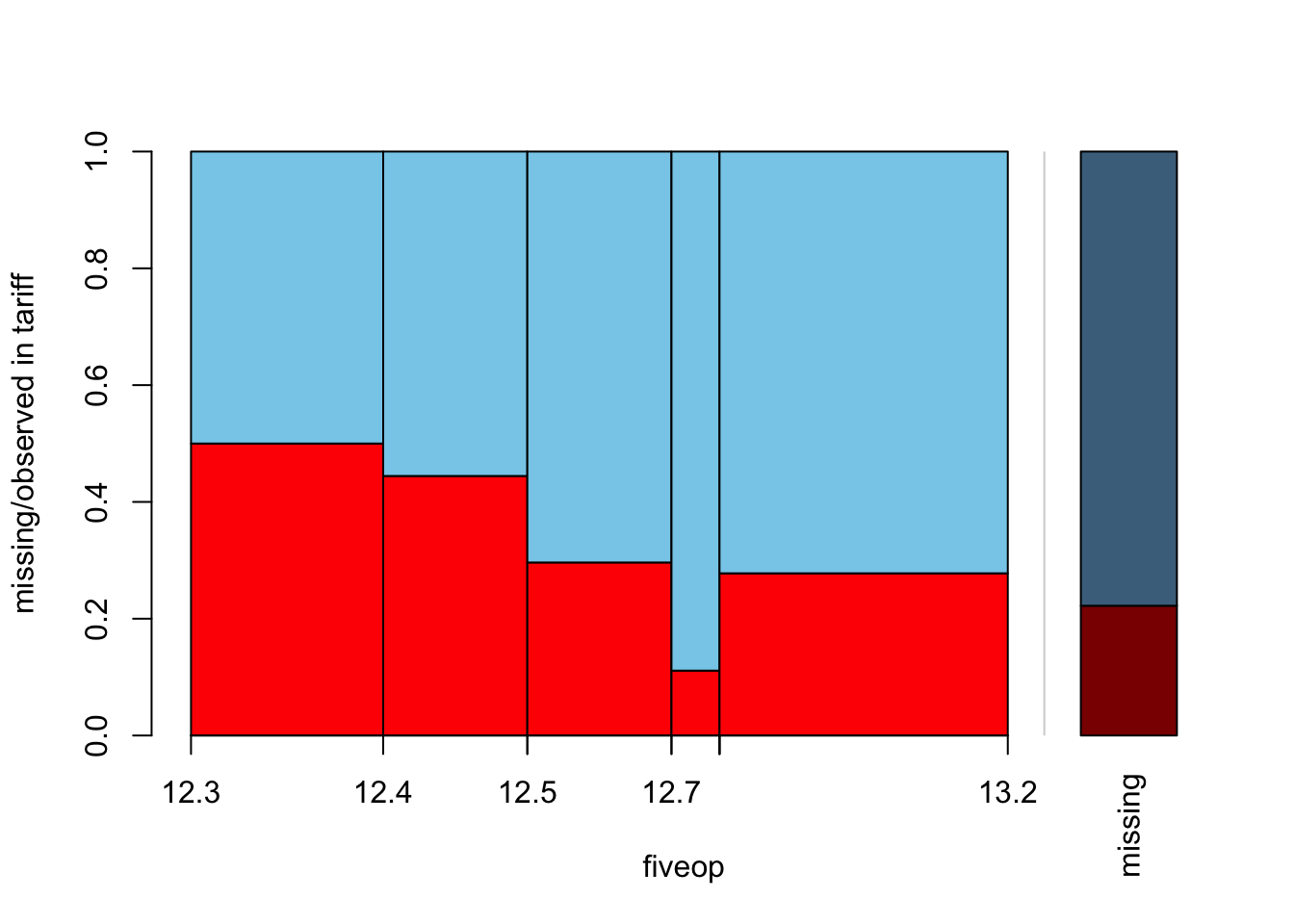
The variable fiveop is a numeric variable, The function automatically creates bins in this plot.
Parallel Boxplot
Parallel boxplots subset the data into two. One for missing values and another for observed values of the supplied variables. In these two subsets the distribution of the second variable is displayed via boxplots. It is particularly useful to understand the pattern of missingness and whether it could possibly be leading to biasing of results if we choose to perform listwise deletion.
pbox(freetrade[, c("tariff", "fiveop")],interactive = FALSE)Warning in createPlot(main, sub, xlab, ylab, labels, ca$at): not enough space
to display frequencies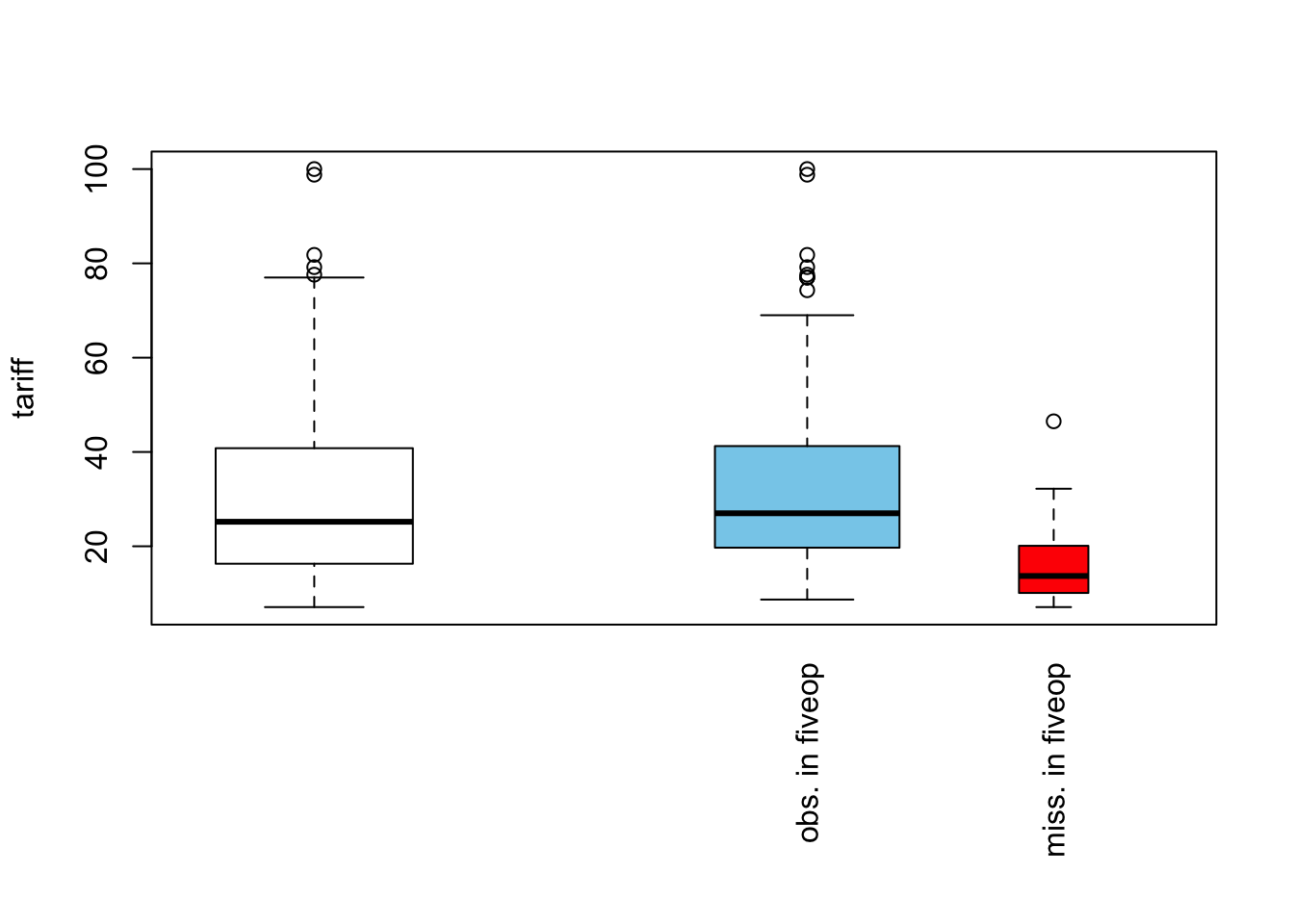
The white box is the overall distribution of tariff in the complete dataset.The blue box represents distribution of tariff for observed values of fiveop and the red box for missing values of fiveop. The relative width of the boxes reflects the sizes of the subsets on which they are based: the wider blue box means there are more observed than missing values in fiveop. Other than that, the two boxes look similar to each other and also the overall white box. This suggests that missing race information has no impact on the distribution of earnings.
While the blue box appears similar to overall plot, the red box shows a distribution different from them. This gives us an indication that the data is not MCAR. The missingness in fiveop is possibly systematically associated to other variables. In the world of MAR and MNAR we would need to be cautious of just dropping the rows with missingness in fiveop.
More functions from VIM graphic utilities here.
ggmicepackage## library(ggmice)
sum(is.na(freetrade$fiveop))[1] 18ggmice(freetrade, aes(gdp.pc,tariff )) + geom_point()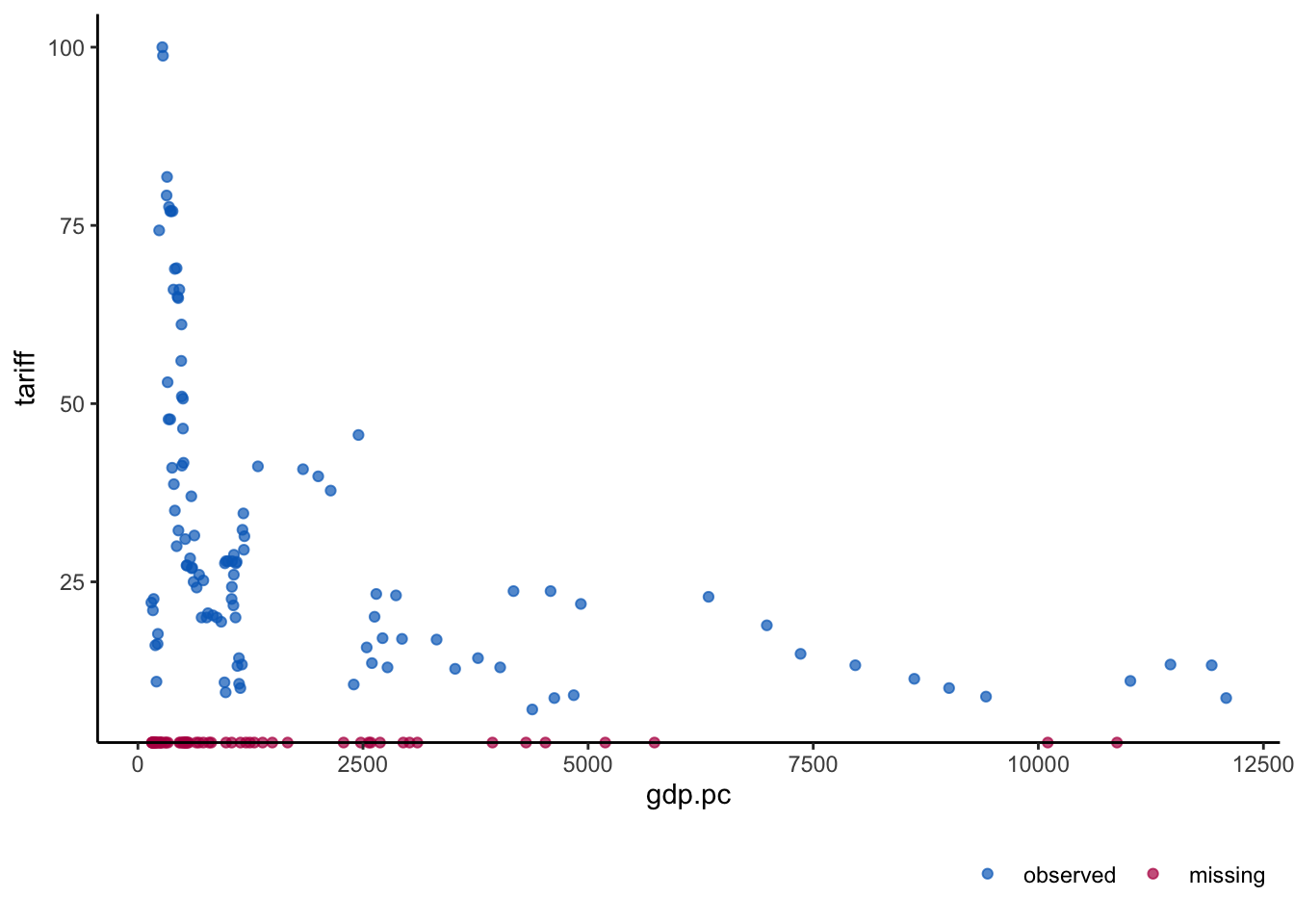
This function can again be useful in seeing patterns in missingness in the data.
The plot above shoes red marks on the x-axis for those values of gdp.pc for which the tariff value on y-axis is missing.
In this case, gdp.pc has no missing values. What if both axes have variables that have missing value. Let’s look at the plot created by VIM to look for two such variables that have jointly missing values.
Let’s use tariff with variable fiveop.
sum(is.na(freetrade$fiveop))[1] 18ggmice(freetrade, aes(fiveop,tariff )) + geom_point()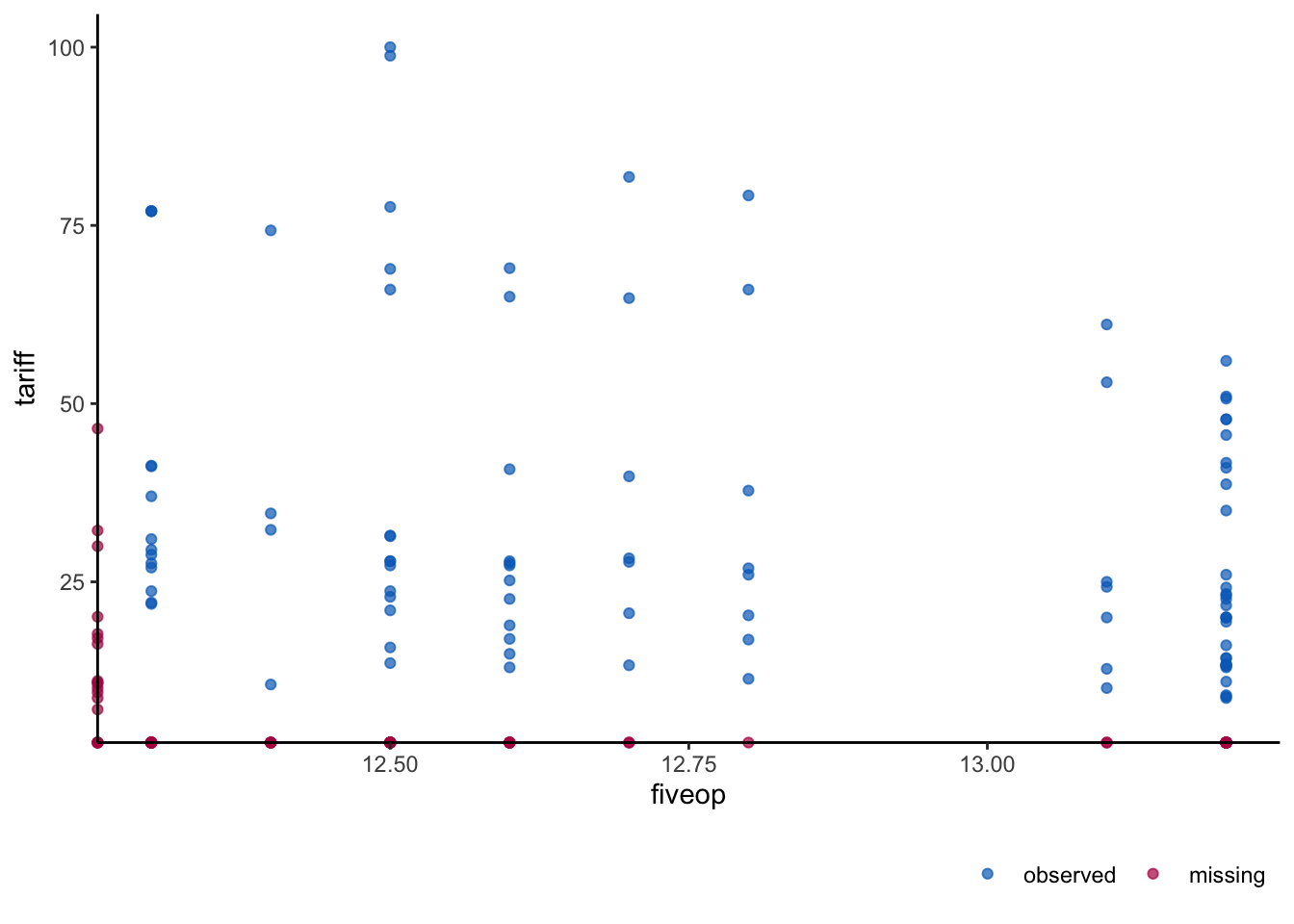
More functionalities in the ggmice package
Most packages perform listwise/case-wise deletion. This is the strategy of complete-case analysis. Revisit the slides from class and Lall (2017) to undertsand why this is pernicious - causes bias and reduces efficiency - in short.
summary(model.lm <- lm(tariff ~ polity + pop + gdp.pc + year + country,
data = freetrade))
Call:
lm(formula = tariff ~ polity + pop + gdp.pc + year + country,
data = freetrade)
Residuals:
Min 1Q Median 3Q Max
-30.7640 -3.2595 0.0868 2.5983 18.3097
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.973e+03 4.016e+02 4.912 3.61e-06 ***
polity -1.373e-01 1.821e-01 -0.754 0.453
pop -2.021e-07 2.542e-08 -7.951 3.23e-12 ***
gdp.pc 6.096e-04 7.442e-04 0.819 0.415
year -8.705e-01 2.084e-01 -4.176 6.43e-05 ***
countryIndonesia -1.823e+02 1.857e+01 -9.819 2.98e-16 ***
countryKorea -2.204e+02 2.078e+01 -10.608 < 2e-16 ***
countryMalaysia -2.245e+02 2.171e+01 -10.343 < 2e-16 ***
countryNepal -2.163e+02 2.247e+01 -9.629 7.74e-16 ***
countryPakistan -1.554e+02 1.982e+01 -7.838 5.63e-12 ***
countryPhilippines -2.040e+02 2.088e+01 -9.774 3.75e-16 ***
countrySriLanka -2.091e+02 2.210e+01 -9.460 1.80e-15 ***
countryThailand -1.961e+02 2.095e+01 -9.358 2.99e-15 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.221 on 98 degrees of freedom
(60 observations deleted due to missingness)
Multiple R-squared: 0.9247, Adjusted R-squared: 0.9155
F-statistic: 100.3 on 12 and 98 DF, p-value: < 2.2e-16#library(estimatr)
summary(model.lm.r <- lm_robust(tariff ~ polity + pop + gdp.pc,
data = freetrade,
fixed_effects = year,
clusters = country))
Call:
lm_robust(formula = tariff ~ polity + pop + gdp.pc, data = freetrade,
clusters = country, fixed_effects = year)
Standard error type: CR2
Coefficients:
Estimate Std. Error t value Pr(>|t|) CI Lower CI Upper DF
polity 9.933e-01 5.954e-01 1.668 0.1963 -9.303e-01 2.917e+00 2.923
pop 3.075e-08 1.850e-08 1.662 0.2449 -5.304e-08 1.145e-07 1.899
gdp.pc -2.168e-03 1.560e-03 -1.390 0.3072 -9.369e-03 5.032e-03 1.865
Multiple R-squared: 0.5238 , Adjusted R-squared: 0.4114
Multiple R-squared (proj. model): 0.415 , Adjusted R-squared (proj. model): 0.277
F-statistic (proj. model): 4.069 on 3 and 8 DF, p-value: 0.04992# Let's see how many observations final models have
nrow(model.lm$model)[1] 111(model.lm.r$nobs)[1] 111A hot-deck imputation is a method for handling missing data where missing values in a dataset are imputed by values from similar records (donors) within the same dataset. The idea is to “borrow” values from observed (non-missing) data. Two common variations are the sequential hot-deck and random hot-deck algorithms.
In the sequential hot-deck method, the missing value is filled with the most recent observed value from a similar case, which is often nearby in the data (usually within sorted rows or groups). In the random hot-deck method, the missing value is imputed by randomly selecting a value from a set of similar cases (donors) that have valid (non-missing) values.
Hot-deck imputation could generally introduce bias is the missing values are too frequent, akin to mean imputation but now with the same value. Sequential imputation is more prone to increased bias as compared to random imputation. The latter generally has more variability in the imputed vector. However, random imputation is computationally more complex. Also, random selection from observed value could lead to varying results depending on the random choice in each new instanc eof imputation on the same dataset.
For more details, read Andridge and Little (2010).
VIM has an inbuilt function for hot-decking called hotdeck().
imputed.freetrade <- hotdeck(freetrade)
summary(model.lm.hotdeck <- lm(tariff ~ polity + pop + gdp.pc + year + country,
data = imputed.freetrade))
Call:
lm(formula = tariff ~ polity + pop + gdp.pc + year + country,
data = imputed.freetrade)
Residuals:
Min 1Q Median 3Q Max
-45.184 -5.439 -1.210 2.490 70.699
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.686e+03 7.285e+02 3.687 0.000311 ***
polity 3.666e-01 3.954e-01 0.927 0.355267
pop 1.998e-08 5.088e-08 0.393 0.695065
gdp.pc 5.779e-04 1.620e-03 0.357 0.721711
year -1.335e+00 3.786e-01 -3.527 0.000551 ***
countryIndonesia -4.457e+00 3.575e+01 -0.125 0.900951
countryKorea -1.919e+01 4.078e+01 -0.471 0.638524
countryMalaysia -1.360e+01 4.208e+01 -0.323 0.746936
countryNepal -7.666e+00 4.312e+01 -0.178 0.859118
countryPakistan 2.481e+01 3.848e+01 0.645 0.520056
countryPhilippines -8.281e+00 4.051e+01 -0.204 0.838302
countrySriLanka -3.307e+00 4.278e+01 -0.077 0.938479
countryThailand 5.206e+00 4.045e+01 0.129 0.897748
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 16.93 on 158 degrees of freedom
Multiple R-squared: 0.4425, Adjusted R-squared: 0.4002
F-statistic: 10.45 on 12 and 158 DF, p-value: 5.079e-15# Check the number of rows
nrow(model.lm.hotdeck$model)[1] 171The imputation can be improved with more substantive knowledge. Read the documentation of function with ?hotdeck.
The paper with detailed discussion of various imoutation methods including K-Nearest Neighbor and Regression Imputation (Kowarik and Templ 2016) has detailed information of hot-decking as well as other imputation methods.
“Lights will guide you home,
And ignite your bones
And I will try to fix you”
- Honaker, King, and Blackwell (2011) responding to Chris Martin while introducing Amelia package
Multiple imputation, is a statistical technique for handling missing data by creating several (multiple) different plausible datasets (imputations), analyzing each of them, and then combining the results to produce estimates that account for the uncertainty introduced by the missing data (Honaker, King, and Blackwell 2011).
Amelia II performs multiple imputations and allows for comuting estimates across multiple imputed datasets while capturing uncertainties at both imputed value as well as multiple datasets.
Which Vairables to choose for Imputation Model
## How many variables? Do we need to go through reduction?
dim(freetrade)[1] 171 10From Amelia Webpage:
When performing multiple imputation, the first step is to identify the variables to include in the imputation model. It is crucial to include at least as much information as will be used in the analysis model. That is, any variable that will be in the analysis model should also be in the imputation model. This includes any transformations or interactions of variables that will appear in the analysis model.
In fact, it is often useful to add more information to the imputation model than will be present when the analysis is run. Since imputation is predictive, any variables that would increase predictive power should be included in the model, even if including them in the analysis model would produce bias in estimating a causal effect (such as for post-treatment variables) or collinearity would preclude determining which variable had a relationship with the dependent variable (such as including multiple alternate measures of GDP). In our case, we include all the variables in freetrade in the imputation model, even though our analysis model focuses on polity, pop and gdp.pc.
How many imputations?
Amelia II creators recommend that unless the rate of missingness is very high in the dataset, m = 5 where m represents number of imputed datsets should be enough (Honaker, King, and Blackwell 2011, pp2). However, in practical applications Lall (2017) suggets to be more cautious of this approach as it could produce some divergence in the results (pp. 426) and suggest calculating \(\gamma\) - the average missignness rate in the dataset - and then chose an \(m\) roughly equal to this rate.
## What is average percentage of missing data?
#m is equal to the average missing-data rate of all variables in the imputation model
NAs <- function(x) {
as.vector(apply(x, 2, function(x) length(which(is.na(x)))))
}
NAs(freetrade) [1] 0 0 58 2 0 0 13 3 18 0mean(NAs(freetrade)/nrow(freetrade))*100[1] 5.497076So, in this case we can safely take \(m=5\).
Creating Imputed Datasets
To create multiple imputations in Amelia, we can simply run
set.seed(20230918)
a.out <- amelia(freetrade,
m = 5,
ts = "year",
cs = "country")-- Imputation 1 --
1 2 3 4 5 6 7 8 9 10 11 12
-- Imputation 2 --
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
-- Imputation 3 --
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
-- Imputation 4 --
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
-- Imputation 5 --
1 2 3 4 5 6 7 8 9 10a.out
Amelia output with 5 imputed datasets.
Return code: 1
Message: Normal EM convergence.
Chain Lengths:
--------------
Imputation 1: 12
Imputation 2: 16
Imputation 3: 16
Imputation 4: 15
Imputation 5: 10The output gives some information about how the algorithm ran. Each of the imputed datasets is now in the list a.out$imputations.
a.out is a list object with 5 imputed datsets stored in it. We can access any of those imputations by using the synatx a.out$imputations[[<number>]] or a.out$imputations$imp<number>.
# See the number of rows
nrow(a.out$imputations$imp1)[1] 171nrow(a.out$imputations[[2]])[1] 171We can access variables in different imputations to coompare the distribution with the original variable’s distribution.
Let’s plot a histogram of the tariff variable from the 3rd imputation,
ggplot(freetrade, aes(tariff)) +geom_histogram()`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 58 rows containing non-finite outside the scale range
(`stat_bin()`).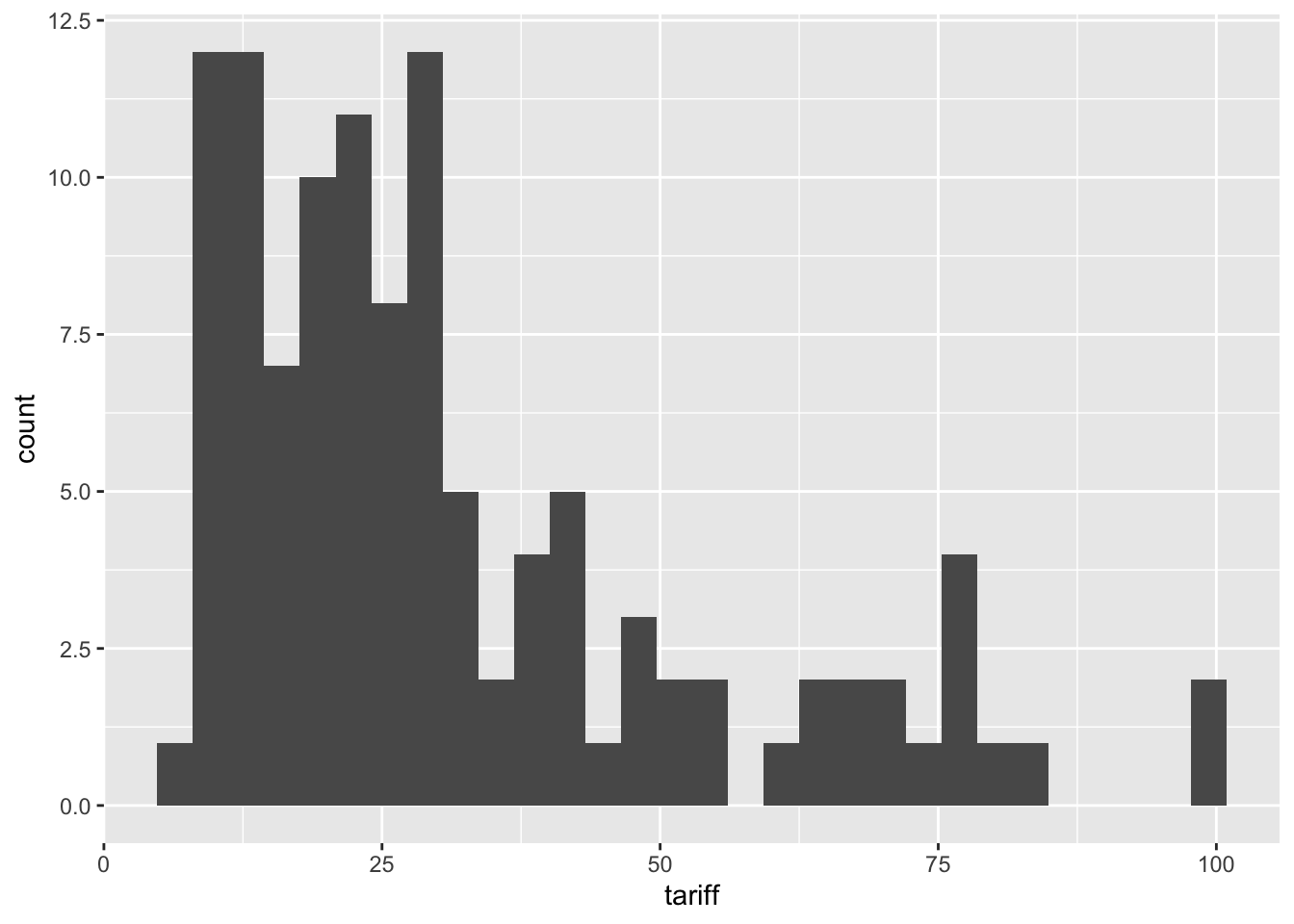
ggplot(a.out$imputations[[3]], aes(tariff)) +geom_histogram()`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.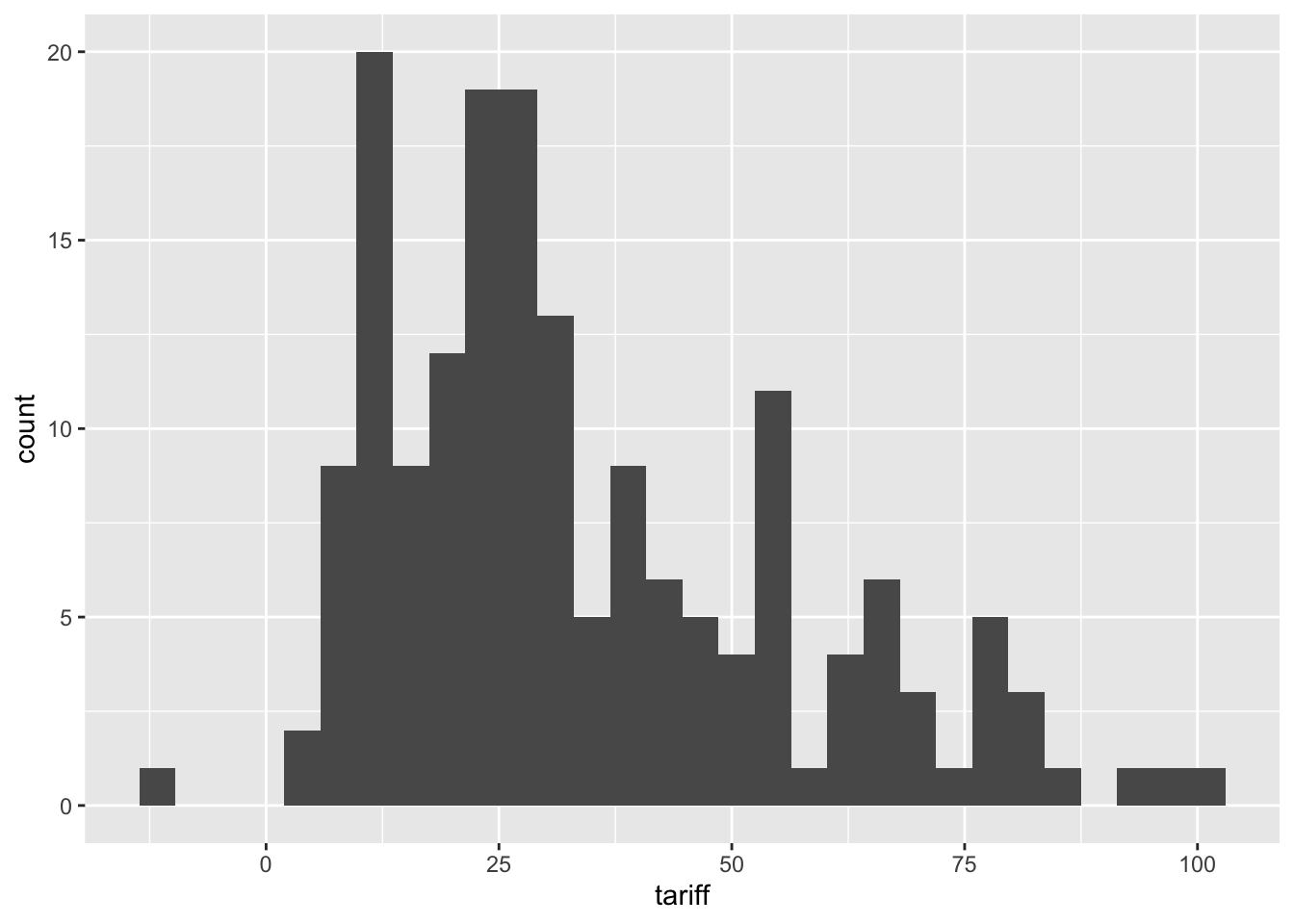
#Compare with original data
comb.tariff <- rbind.data.frame(
cbind(tariff = a.out$imputations[[3]]$tariff, df = "impute.3"),
cbind(tariff = freetrade$tariff, df = "original")) %>%
mutate( tariff = as.numeric(tariff))
ggplot(comb.tariff, aes(tariff, fill = df)) +geom_histogram(position = 'identity', alpha = 0.6, color = "black")`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 58 rows containing non-finite outside the scale range
(`stat_bin()`).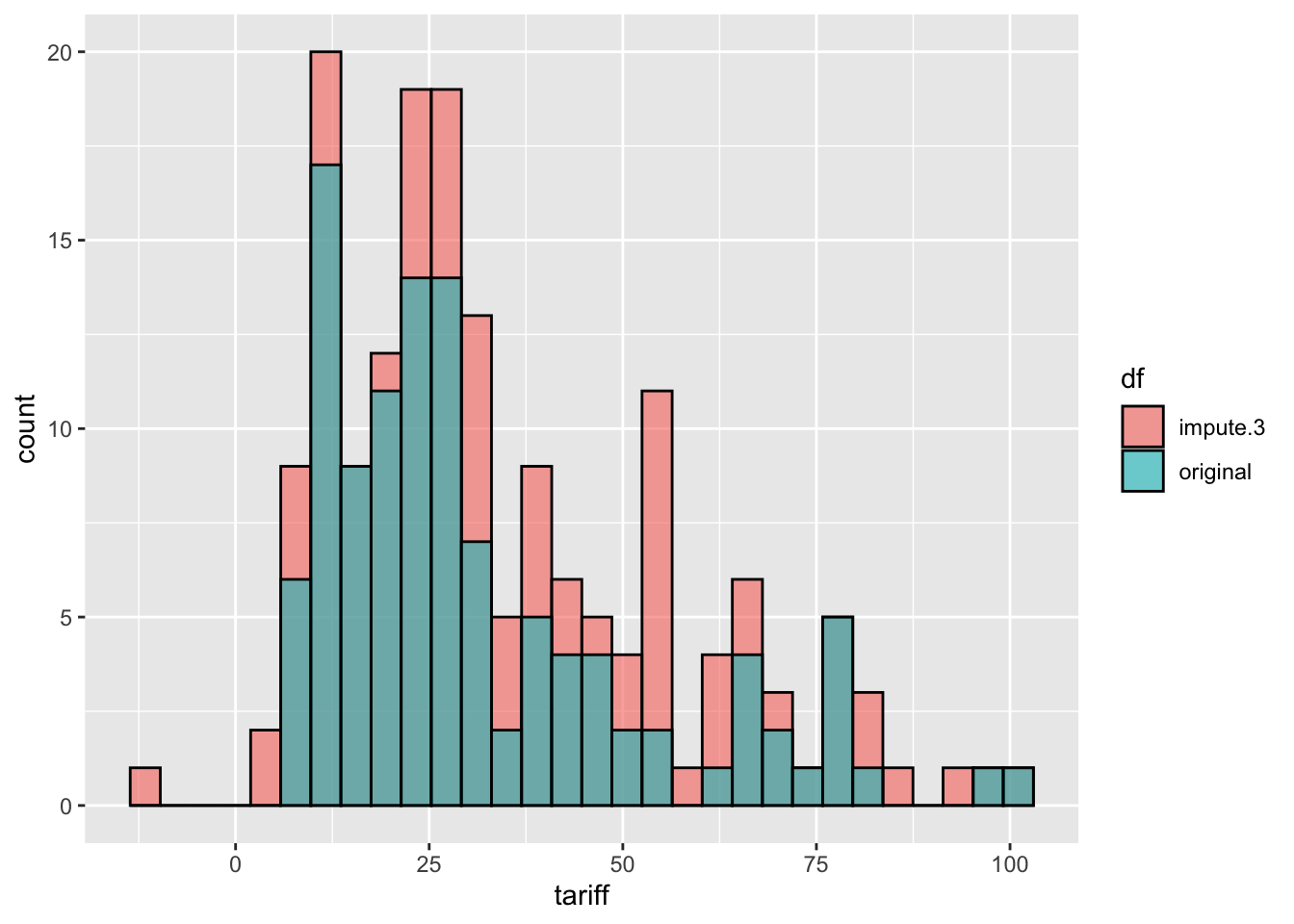
Saving the imputed datasets
```{r}
save(a.out, file = "imputations.RData") # .RData file
write.amelia(obj = a.out, file.stem = "imputation-freetrade") # As five separate csvs
```Expansive Function
# More expansive model
# Amelia model
# as2012.out <- amelia(freetrade, # data
# m = 5, # number of imputations
# ts = "year", # time series index
# cs = "country", # cross section index
# polytime = 3, # third-order time polynomial
# lags = c("polity", "gdp.pc"), # lag variable
# ords = "polity" # Ordinal Variable
# noms = "polity" # If polity was a nominal variable
# empri = 0.01*nrow(as)) # priors
# Not running, just for explanationAlso, read sections on transformations,bounds, time-series-cross-section data (TSCS) and id-variables from the Amelia Website
# Recall the Linear Models we ran above
summary(model.lm)
Call:
lm(formula = tariff ~ polity + pop + gdp.pc + year + country,
data = freetrade)
Residuals:
Min 1Q Median 3Q Max
-30.7640 -3.2595 0.0868 2.5983 18.3097
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.973e+03 4.016e+02 4.912 3.61e-06 ***
polity -1.373e-01 1.821e-01 -0.754 0.453
pop -2.021e-07 2.542e-08 -7.951 3.23e-12 ***
gdp.pc 6.096e-04 7.442e-04 0.819 0.415
year -8.705e-01 2.084e-01 -4.176 6.43e-05 ***
countryIndonesia -1.823e+02 1.857e+01 -9.819 2.98e-16 ***
countryKorea -2.204e+02 2.078e+01 -10.608 < 2e-16 ***
countryMalaysia -2.245e+02 2.171e+01 -10.343 < 2e-16 ***
countryNepal -2.163e+02 2.247e+01 -9.629 7.74e-16 ***
countryPakistan -1.554e+02 1.982e+01 -7.838 5.63e-12 ***
countryPhilippines -2.040e+02 2.088e+01 -9.774 3.75e-16 ***
countrySriLanka -2.091e+02 2.210e+01 -9.460 1.80e-15 ***
countryThailand -1.961e+02 2.095e+01 -9.358 2.99e-15 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.221 on 98 degrees of freedom
(60 observations deleted due to missingness)
Multiple R-squared: 0.9247, Adjusted R-squared: 0.9155
F-statistic: 100.3 on 12 and 98 DF, p-value: < 2.2e-16summary(model.lm.r)
Call:
lm_robust(formula = tariff ~ polity + pop + gdp.pc, data = freetrade,
clusters = country, fixed_effects = year)
Standard error type: CR2
Coefficients:
Estimate Std. Error t value Pr(>|t|) CI Lower CI Upper DF
polity 9.933e-01 5.954e-01 1.668 0.1963 -9.303e-01 2.917e+00 2.923
pop 3.075e-08 1.850e-08 1.662 0.2449 -5.304e-08 1.145e-07 1.899
gdp.pc -2.168e-03 1.560e-03 -1.390 0.3072 -9.369e-03 5.032e-03 1.865
Multiple R-squared: 0.5238 , Adjusted R-squared: 0.4114
Multiple R-squared (proj. model): 0.415 , Adjusted R-squared (proj. model): 0.277
F-statistic (proj. model): 4.069 on 3 and 8 DF, p-value: 0.04992# Now running with imputed datasets
imp.models <- with( # Note this command
a.out,
lm(tariff ~ polity + pop + gdp.pc + year + country)
)
# Analysis results with five imputed datsets
imp.models[1:5][[1]]
Call:
lm(formula = tariff ~ polity + pop + gdp.pc + year + country)
Coefficients:
(Intercept) polity pop gdp.pc
3.402e+03 1.314e-01 -1.253e-07 5.026e-04
year countryIndonesia countryKorea countryMalaysia
-1.624e+00 -1.138e+02 -1.522e+02 -1.517e+02
countryNepal countryPakistan countryPhilippines countrySriLanka
-1.384e+02 -9.973e+01 -1.398e+02 -1.370e+02
countryThailand
-1.311e+02
[[2]]
Call:
lm(formula = tariff ~ polity + pop + gdp.pc + year + country)
Coefficients:
(Intercept) polity pop gdp.pc
3.080e+03 6.137e-02 -4.630e-08 -2.889e-04
year countryIndonesia countryKorea countryMalaysia
-1.500e+00 -5.777e+01 -7.636e+01 -7.796e+01
countryNepal countryPakistan countryPhilippines countrySriLanka
-6.808e+01 -3.119e+01 -6.796e+01 -6.195e+01
countryThailand
-6.287e+01
[[3]]
Call:
lm(formula = tariff ~ polity + pop + gdp.pc + year + country)
Coefficients:
(Intercept) polity pop gdp.pc
2.769e+03 1.266e-01 -1.298e-07 -6.143e-04
year countryIndonesia countryKorea countryMalaysia
-1.304e+00 -1.204e+02 -1.455e+02 -1.502e+02
countryNepal countryPakistan countryPhilippines countrySriLanka
-1.459e+02 -1.010e+02 -1.419e+02 -1.353e+02
countryThailand
-1.341e+02
[[4]]
Call:
lm(formula = tariff ~ polity + pop + gdp.pc + year + country)
Coefficients:
(Intercept) polity pop gdp.pc
2.517e+03 6.279e-02 -1.128e-07 3.814e-04
year countryIndonesia countryKorea countryMalaysia
-1.186e+00 -1.081e+02 -1.403e+02 -1.358e+02
countryNepal countryPakistan countryPhilippines countrySriLanka
-1.304e+02 -8.434e+01 -1.260e+02 -1.245e+02
countryThailand
-1.192e+02
[[5]]
Call:
lm(formula = tariff ~ polity + pop + gdp.pc + year + country)
Coefficients:
(Intercept) polity pop gdp.pc
2.498e+03 9.533e-02 -2.128e-08 -4.360e-04
year countryIndonesia countryKorea countryMalaysia
-1.219e+00 -3.874e+01 -5.313e+01 -5.325e+01
countryNepal countryPakistan countryPhilippines countrySriLanka
-5.009e+01 -1.167e+01 -4.665e+01 -3.946e+01
countryThailand
-3.571e+01 # Similarly, lm_robust can be run with approprite modifications
# BTW, see the class of created object
class(imp.models)[1] "amest"We can combine the imputed estimates using Rubin Rules (Lall 2017; Honaker, King, and Blackwell 2011).
out <- mi.combine(imp.models, conf.int = TRUE)
out# A tibble: 13 × 10
term estimate std.error statistic p.value df r miss.info conf.low
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Inter… 2.85e+3 6.87e+2 4.15 2.86e-4 2.76e1 0.615 0.421 4.26e+3
2 polity 9.55e-2 2.98e-1 0.321 7.48e-1 1.73e4 0.0155 0.0153 6.79e-1
3 pop -8.71e-8 6.65e-8 -1.31 1.78e+0 8.78e0 2.08 0.730 6.38e-8
4 gdp.pc -9.10e-5 1.33e-3 -0.0685 1.05e+0 1.37e2 0.206 0.183 2.54e-3
5 year -1.37e+0 3.49e-1 -3.92 2.00e+0 3.25e1 0.541 0.387 -6.57e-1
6 countr… -8.78e+1 4.84e+1 -1.81 1.89e+0 8.21e0 2.31 0.752 2.35e+1
7 countr… -1.13e+2 5.84e+1 -1.94 1.91e+0 7.56e0 2.67 0.779 2.25e+1
8 countr… -1.14e+2 5.87e+1 -1.94 1.91e+0 7.84e0 2.50 0.767 2.20e+1
9 countr… -1.07e+2 5.81e+1 -1.84 1.90e+0 8.30e0 2.27 0.748 2.65e+1
10 countr… -6.56e+1 5.37e+1 -1.22 1.74e+0 7.83e0 2.51 0.768 5.86e+1
11 countr… -1.04e+2 5.70e+1 -1.83 1.89e+0 7.72e0 2.57 0.772 2.78e+1
12 countr… -9.97e+1 5.93e+1 -1.68 1.87e+0 7.91e0 2.46 0.764 3.73e+1
13 countr… -9.66e+1 5.74e+1 -1.68 1.87e+0 7.62e0 2.63 0.776 3.69e+1
# ℹ 1 more variable: conf.high <dbl># Compare with models with missing data
tidy(model.lm)# A tibble: 13 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 1.97e+3 4.02e+2 4.91 3.61e- 6
2 polity -1.37e-1 1.82e-1 -0.754 4.53e- 1
3 pop -2.02e-7 2.54e-8 -7.95 3.23e-12
4 gdp.pc 6.10e-4 7.44e-4 0.819 4.15e- 1
5 year -8.71e-1 2.08e-1 -4.18 6.43e- 5
6 countryIndonesia -1.82e+2 1.86e+1 -9.82 2.98e-16
7 countryKorea -2.20e+2 2.08e+1 -10.6 5.82e-18
8 countryMalaysia -2.25e+2 2.17e+1 -10.3 2.19e-17
9 countryNepal -2.16e+2 2.25e+1 -9.63 7.74e-16
10 countryPakistan -1.55e+2 1.98e+1 -7.84 5.63e-12
11 countryPhilippines -2.04e+2 2.09e+1 -9.77 3.75e-16
12 countrySriLanka -2.09e+2 2.21e+1 -9.46 1.80e-15
13 countryThailand -1.96e+2 2.10e+1 -9.36 2.99e-15tidy(model.lm.r) term estimate std.error statistic p.value conf.low
1 polity 9.932974e-01 5.954310e-01 1.668199 0.1962662 -9.302831e-01
2 pop 3.074611e-08 1.849543e-08 1.662363 0.2448695 -5.304187e-08
3 gdp.pc -2.168425e-03 1.559823e-03 -1.390174 0.3071929 -9.368722e-03
conf.high df outcome
1 2.916878e+00 2.922744 tariff
2 1.145341e-07 1.898740 tariff
3 5.031871e-03 1.864708 tarifftidy(model.lm.hotdeck)# A tibble: 13 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 2.69e+3 7.29e+2 3.69 0.000311
2 polity 3.67e-1 3.95e-1 0.927 0.355
3 pop 2.00e-8 5.09e-8 0.393 0.695
4 gdp.pc 5.78e-4 1.62e-3 0.357 0.722
5 year -1.34e+0 3.79e-1 -3.53 0.000551
6 countryIndonesia -4.46e+0 3.58e+1 -0.125 0.901
7 countryKorea -1.92e+1 4.08e+1 -0.471 0.639
8 countryMalaysia -1.36e+1 4.21e+1 -0.323 0.747
9 countryNepal -7.67e+0 4.31e+1 -0.178 0.859
10 countryPakistan 2.48e+1 3.85e+1 0.645 0.520
11 countryPhilippines -8.28e+0 4.05e+1 -0.204 0.838
12 countrySriLanka -3.31e+0 4.28e+1 -0.0773 0.938
13 countryThailand 5.21e+0 4.04e+1 0.129 0.898 # Install required packages if you haven't already
# install.packages(c("dplyr", "kableExtra", "tidyr"))
library(broom)
# Assuming tidy outputs from the three models
tidy_lm <- tidy(model.lm)
tidy_lm_hotdeck <- tidy(model.lm.hotdeck)
tidy_amelia <- out
# Combine the tidy outputs into one data frame with model names
combined_tidy <- bind_rows(
tidy_lm %>% mutate(Model = "Complete-Case Model"),
tidy_lm_hotdeck %>% mutate(Model = "Hot-Deck Model"),
tidy_amelia %>% mutate(Model = "Amelia MI Model")
)
# Reshape the data to wide format
wide_tidy <- combined_tidy %>%
select(Model, term, estimate, std.error, statistic, p.value) %>%
pivot_wider(names_from = Model, values_from = c(estimate, std.error, statistic, p.value),
names_sep = "_") # This will create column names like estimate_Complete-Case Model
# Create LaTeX table using kableExtra
wide_tidy %>%
kbl( booktabs = TRUE, caption = "Combined Regression Models (Transposed)") %>%
kable_styling(latex_options = c("hold_position", "striped"))| term | estimate_Complete-Case Model | estimate_Hot-Deck Model | estimate_Amelia MI Model | std.error_Complete-Case Model | std.error_Hot-Deck Model | std.error_Amelia MI Model | statistic_Complete-Case Model | statistic_Hot-Deck Model | statistic_Amelia MI Model | p.value_Complete-Case Model | p.value_Hot-Deck Model | p.value_Amelia MI Model |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Intercept) | 1972.6328639 | 2686.2632874 | 2853.2141618 | 401.6146966 | 728.5197908 | 687.1615407 | 4.9117547 | 3.6872894 | 4.1521738 | 0.0000036 | 0.0003112 | 0.0002857 |
| polity | -0.1372722 | 0.3665900 | 0.0955053 | 0.1821269 | 0.3953980 | 0.2975730 | -0.7537175 | 0.9271417 | 0.3209475 | 0.4528260 | 0.3552670 | 0.7482541 |
| pop | -0.0000002 | 0.0000000 | -0.0000001 | 0.0000000 | 0.0000001 | 0.0000001 | -7.9508396 | 0.3927075 | -1.3103516 | 0.0000000 | 0.6950648 | 1.7766806 |
| gdp.pc | 0.0006096 | 0.0005779 | -0.0000910 | 0.0007442 | 0.0016196 | 0.0013298 | 0.8191485 | 0.3568093 | -0.0684692 | 0.4146893 | 0.7217106 | 1.0544879 |
| year | -0.8705461 | -1.3352910 | -1.3667123 | 0.2084439 | 0.3786027 | 0.3487968 | -4.1764050 | -3.5268924 | -3.9183625 | 0.0000643 | 0.0005506 | 1.9995679 |
| countryIndonesia | -182.3267131 | -4.4570567 | -87.7626156 | 18.5678981 | 35.7538047 | 48.4445877 | -9.8194590 | -0.1246596 | -1.8116083 | 0.0000000 | 0.9009515 | 1.8933361 |
| countryKorea | -220.4438668 | -19.1943113 | -113.4919900 | 20.7803472 | 40.7806642 | 58.3744290 | -10.6082860 | -0.4706719 | -1.9442073 | 0.0000000 | 0.6385242 | 1.9101103 |
| countryMalaysia | -224.5464768 | -13.6016471 | -113.7811609 | 21.7107818 | 42.0782935 | 58.6693456 | -10.3426251 | -0.3232462 | -1.9393630 | 0.0000000 | 0.7469362 | 1.9108244 |
| countryNepal | -216.3338310 | -7.6660915 | -106.5699358 | 22.4672149 | 43.1194970 | 58.0575005 | -9.6288673 | -0.1777871 | -1.8355929 | 0.0000000 | 0.8591179 | 1.8976104 |
| countryPakistan | -155.3509868 | 24.8052485 | -65.5886664 | 19.8214313 | 38.4755650 | 53.6629118 | -7.8375262 | 0.6447013 | -1.2222346 | 0.0000000 | 0.5200557 | 1.7428515 |
| countryPhilippines | -204.0378373 | -8.2807140 | -104.4628202 | 20.8758293 | 40.5117099 | 56.9810714 | -9.7738794 | -0.2044030 | -1.8332899 | 0.0000000 | 0.8383017 | 1.8945536 |
| countrySriLanka | -209.0534653 | -3.3074333 | -99.6524394 | 22.0994094 | 42.7842325 | 59.2852871 | -9.4596856 | -0.0773050 | -1.6808966 | 0.0000000 | 0.9384788 | 1.8682816 |
| countryThailand | -196.0930793 | 5.2063126 | -96.6075914 | 20.9539028 | 40.4488334 | 57.3985862 | -9.3583082 | 0.1287135 | -1.6831005 | 0.0000000 | 0.8977480 | 1.8672833 |
# Filter out the intercept, as it's typically not included in coefficient plots
combined_tidy_filtered <- combined_tidy %>%
filter(term != "(Intercept)") %>%
filter(!str_detect(term,"^country"))
# Create the coefficient plot
ggplot(combined_tidy_filtered, aes(x = term, y = estimate, color = Model)) +
geom_point(position = position_dodge(width = 0.5)) + # Points for estimates
geom_errorbar(aes(ymin = estimate - std.error, ymax = estimate + std.error),
width = 0.2, position = position_dodge(width = 0.5)) + # Error bars for std errors
labs(title = "Coefficient Plot of Combined Models",
x = "Term",
y = "Estimate",
color = "Model") +
theme_minimal() +
coord_flip() # Flip coordinates for better readability (optional)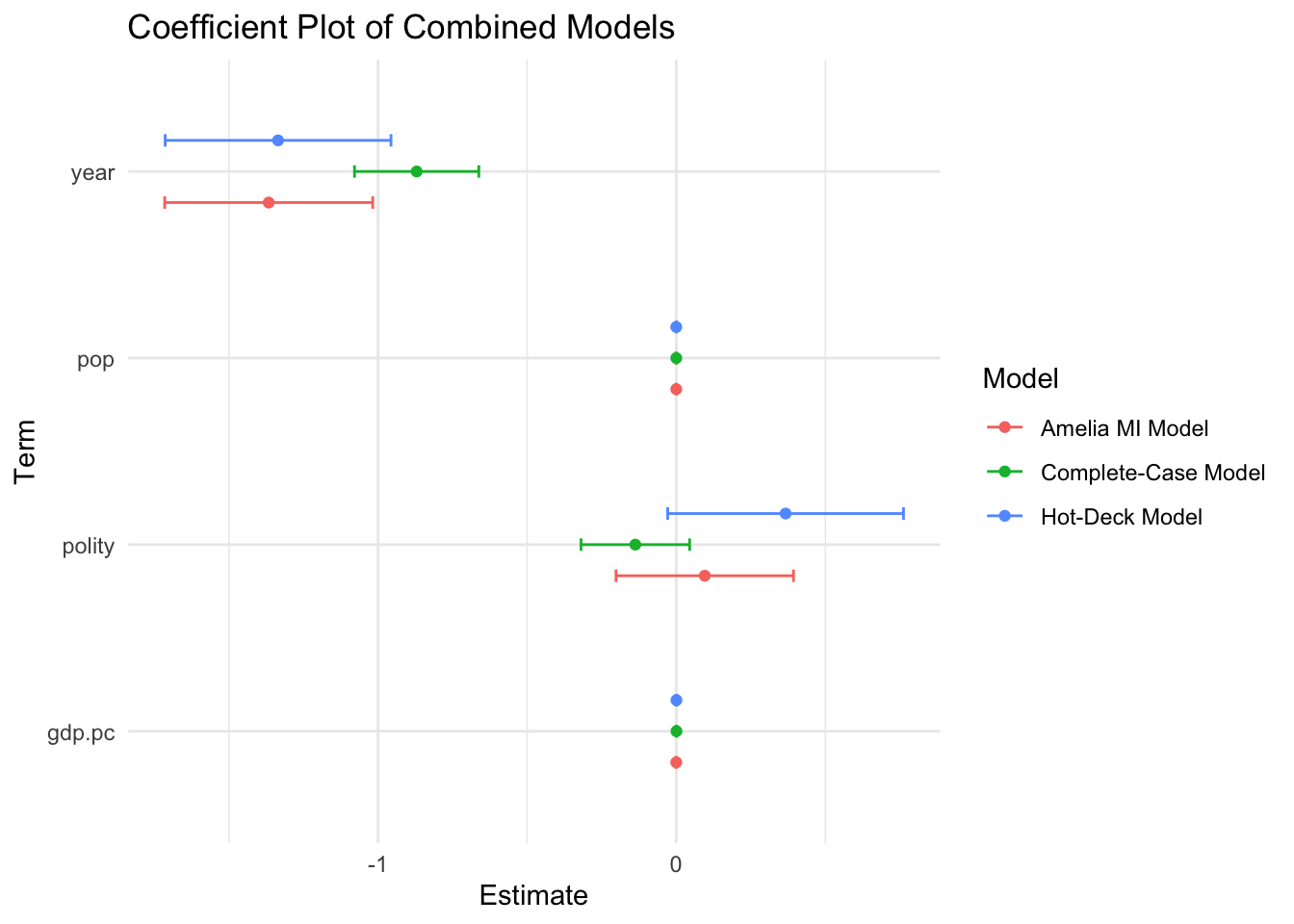
# Just country fixed effects
combined_tidy_filtered_fe <- combined_tidy %>%
filter(str_detect(term,"^country"))
# Create the coefficient plot
ggplot(combined_tidy_filtered_fe, aes(x = term, y = estimate, color = Model)) +
geom_point(position = position_dodge(width = 0.5)) + # Points for estimates
geom_errorbar(aes(ymin = estimate - std.error, ymax = estimate + std.error),
width = 0.2, position = position_dodge(width = 0.5)) + # Error bars for std errors
labs(title = "Coefficient Plot of Combined Models",
x = "Term",
y = "Estimate",
color = "Model") +
theme_minimal() +
coord_flip() # Flip coordinates for better readability (optional)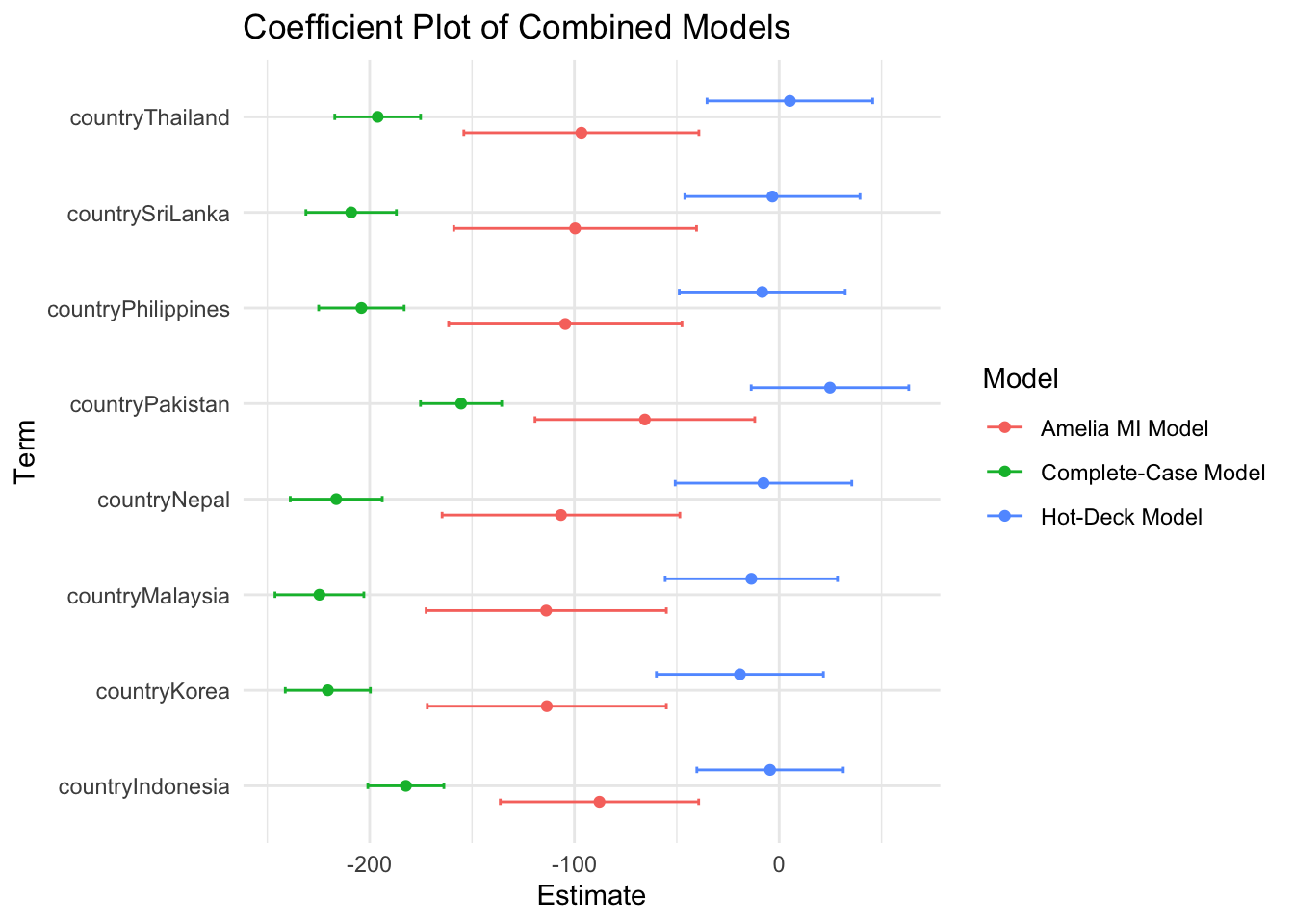
Any idea why the name is AMELIA?
Additional Resources
Note on Expectation Utilization Algorithm (King et al. 2001) which is employed in Amelia II.
EM Algorithm for Multiple Imputation
The Expectation-Maximization (EM) algorithm is a method for finding the maximum likelihood estimate of parameters in a statistical model when there is missing data. It’s an iterative process that involves two steps:
Expectation Step (E-step): In this step, the expected value of the complete-data log-likelihood function is calculated, conditional on the observed data and the current parameter estimates. This step imputes the missing data using predicted values based on the current parameter estimates.
Maximization Step (M-step): This step involves maximizing the expected complete-data log-likelihood function with respect to the parameters. The updated parameter estimates are then used in the next E-step.
In the context of multiple imputation, the EM algorithm is used to estimate the parameters of the multivariate normal distribution assumed to underlie the data. These estimated parameters are then used to generate imputations for the missing data.
The EM algorithm has several advantages, including:
Speed: EM is faster than other multiple imputation algorithms like the Imputation-Posterior (IP) algorithm.
Deterministic Convergence: EM converges deterministically, meaning that the objective function increases with every iteration and it avoids the convergence issues associated with stochastic algorithms like IP.
However, EM also has some drawbacks:
Limited Output: EM only yields maximum posterior estimates of the parameters, rather than the entire posterior distribution.
Potential Bias: Using EM for multiple imputation can lead to biased estimates and downwardly biased standard errors because it ignores estimation uncertainty in the parameters.
The modifications to original EM algorithm include:
EMs (EM with sampling): This method uses the asymptotic approximation of the posterior distribution of the parameters to generate multiple imputations. It is fast and produces independent imputations but can be inaccurate in small samples or with a large number of variables.
EMis (EM with importance resampling): This method uses importance resampling to improve the small sample performance of EMs by approximating the true (finite sample) posterior distribution of the parameters. EMis retains the advantages of IP and addresses the limitations of EM and EMs.