“Yes, and how many years must a mountain exist,
Before it is washed to the sea?”,
- Bob Dylan and Joan Baez, untangling the concept of sensitivity of parameter estimates [mountain] in relative terms [year] before the effect size is reduced to zero [washed to the sea], in Blowin’ in the wind Picture Source
Material
Download the 8003-Sensitivity-Mediation Lab folder from here.
The links above redirect to online vignettes or paper that have the expanded codes and writeup used in today’s lab.
Sensitivity Analysis
A technique for assessing the robustness of research findings to the potential influence of unobserved confounders.
Understanding from an Omitted Variable Bias Approach1
Idea: How strong unobserved factor/s have to be to question our research conclusions (or at least provoke a rethinking)?
Or Put Differently:
How far along our results would hold before they are threatened by possible unobserved factors?
But..
Unobserved are well unobserved, so how do we quantify them?
Ans: In relative terms. That is, as some number of times of the observed controls.
As discussed in class, this has clear resemblance to discussion on Omitted Variable Bias. For a thorough conceptual reading, refer to Cinelli, Ferwerda, and Hazlett (n.d.) and Cinelli and Hazlett (2020).
Code
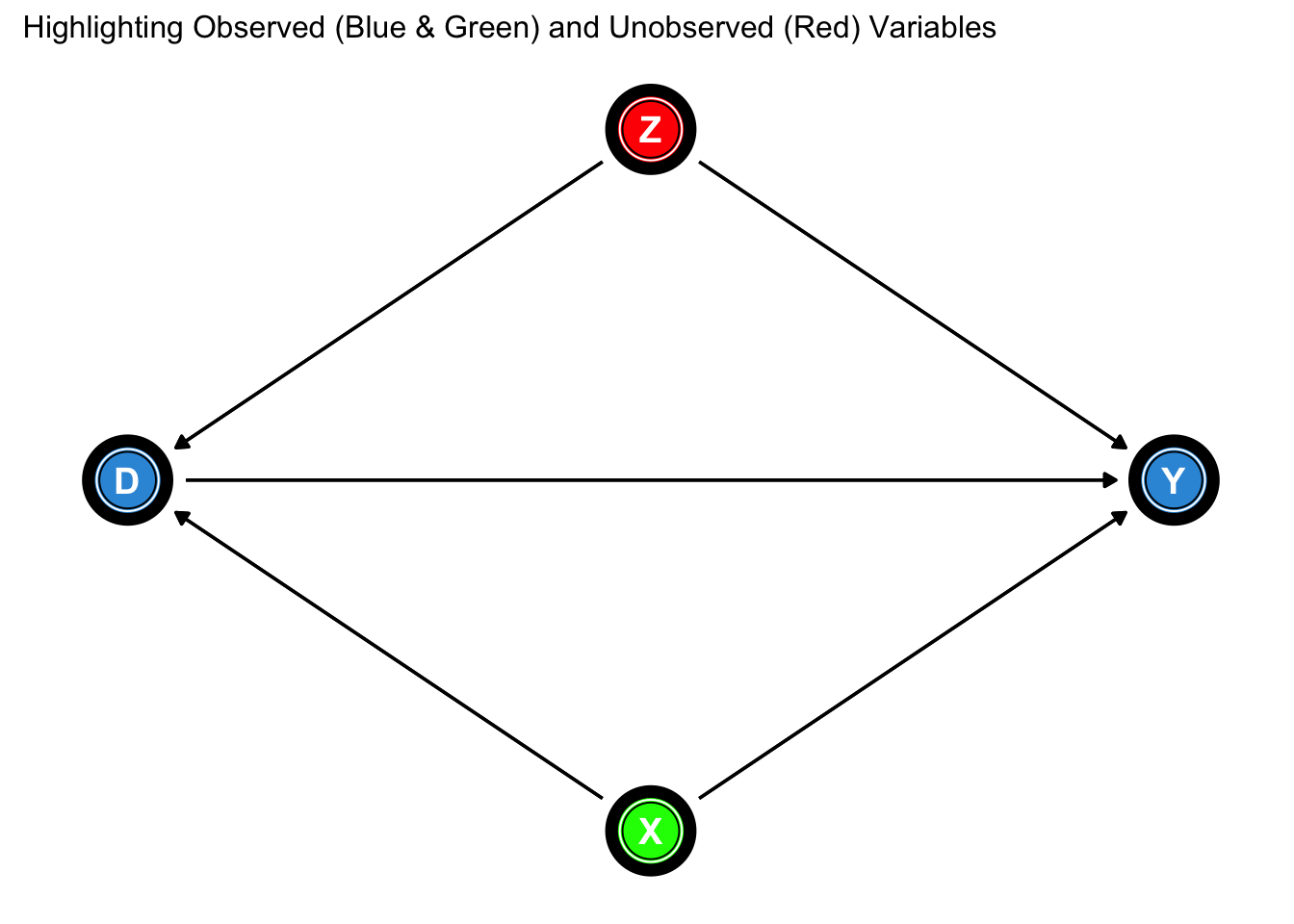
# Load required packageslibrary(dagitty)library(ggdag)library(ggplot2)library(dplyr)# Create the updated DAG using dagittydag <-dagitty("dag { D -> Y Z -> D Z -> Y X -> D X -> Y}")# Set layout coordinates for nodescoordinates(dag) <-list(x =c(D =1, Y =3, Z =2, X =2),y =c(D =2, Y =2, Z =3, X =1))# Convert the DAG to ggdag formattidy_dag <-tidy_dagitty(dag)# Add node type and colorstidy_dag <- tidy_dag %>%mutate(node_type =case_when( name =="Z"~"Unobserved",TRUE~"Observed" ),node_color =case_when( name =="Z"~"red", # Unobserved name =="X"~"green", # Observed confounderTRUE~"#3498db"# Other observed variables ))# Plot the DAG with colors and a legendggdag(tidy_dag, text =TRUE) +geom_dag_edges(size =1.2) +geom_dag_node(aes(fill = node_color), color ="black", size =12, shape =21) +geom_dag_text(color ="white", size =5, fontface ="bold") +theme_dag() +labs(subtitle ="Highlighting Observed (Blue & Green) and Unobserved (Red) Variables",fill ="Node Type" ) +scale_fill_identity() +theme(plot.title =element_text(face ="bold", size =16),plot.subtitle =element_text(size =12),legend.position ="right" )
If this is the Data Generating Mechanism or the true state of the world,
\[
Y = \hat\tau D +\boldsymbol{X}\hat\beta + \hat\gamma Z + \epsilon ....(1)
\] where Y is an n × 1 vector containing the outcome of interest for each of the n observations and D is an n × 1 treatment variable (which may be continuous or binary); X is an n × p matrix of observed (pretreatment) covariates including the constant; and Z is a single n × 1 unobserved covariate. However, since Z is unobserved, we are forced instead to estimate a restricted model:
\[
Y = \hat\tau_{res} D +\boldsymbol{X}\hat\beta_{res} + \hat\epsilon_{res}
\] where \(\tau_{res}\) and \(\beta_{res}\) are the coefficient estimates of the restricted ordinary least squares with only D and X, omitting Z, and \(\epsilon_{res}\) its corresponding residual.
\[
\hat\tau_{res} = \hat\tau + \hat\gamma\hat\delta
\] where \(\hat\delta\) is the coefficient on observed and included covariate \(X\) in auxillary regression.
Thus, bias is.
\[
\hat{Bias} = \hat\gamma\hat\delta
\] This recall of OVB provides intuition for sensitivity analysis. Omission of \(Z\) affects determination of causality i.e. equation (1) has causal meaning only when \(Z\) is included. As we have gone through lectures, if \(Z\) is a confoudner, the supposedly causal effect of D is biased, unless it is included.
However, as true in observational studies, while theoretically \(Z\) si needed, in any instance of data collection it might be unobserved. Yet this does not preclude it from true scientific inquiry and consequentially, nor from peer/reviewer comments.
Sensitivity analysis uses the idea of qunatifying the magnitude of bias in terms of statistics obtained in the restricted model for observed covrariates (\(X\) in above model). In case of a single binary \(X\) it could be said that a possible unobserved confounder \(Z\), if has an effect size of \(k\) times of \(\hat\beta_{res}\), would soak away all the effect. However, in case of multiple \(Xs\) and an unknown number of \(Zs\), both of which could be continuous, the OVB characterization of effect size comparisions could fail to provide interpretatble answers.
Cinelli and Hazlett (2020) reparameterize the OVB formula, to partial \(R^2\) values and other derivative sensitivity statistics, instead of of observed effect sizes in restricted model.
Sensitivity Statistics.
Partial\(R^2\) The proportion of variation in a dependent variable explained by an independent variable after controlling for other independent variables.
Robustness Value (RV) The minimum strength of association, measured in partial R2, that an unobserved confounder would need to have with both the treatment and the outcome to change the research conclusions. In essence, it tells you how strong the unobserved confounder needs to be to nullify the observed effect.
Bounding: A method for limiting the plausible range of values for the strength of association between an unobserved confounder and the treatment or outcome
How to perform sensitivity analysis
We will use Hazlett (2020) as an illustrative example. The code and text below is adapted from the sensemakr vignette.
Paper:
Hazlett, C. (2020). Angry or Weary? How Violence Impacts Attitudes toward Peace among Darfurian Refugees. The Journal of Conflict Resolution, 64(5), 844–870. https://www.jstor.org/stable/48596931
Abstract:
Does exposure to violence motivate individuals to support further violence or to seek peace? Such questions are central to our understanding of how conflicts evolve, terminate, and recur. Yet, convincing empirical evidence as to which response dominates—even in a specific case—has been elusive, owing to the inability to rule out confounding biases. This article employs a natural experiment based on the indiscriminacy of violence within villages in Darfur to examine how refugees’ experiences of violence affect their attitudes toward peace. The results are consistent with a pro-peace or “weary” response: individuals directly harmed by violence were more likely to report that peace is possible and less likely to demand execution of their enemies. This provides microlevel evidence supporting earlier country-level work on “war-weariness” and extends the growing literature on the effects of violence on individuals by including attitudes toward peace as an important outcome. These findings suggest that victims harmed by violence during war can play a positive role in settlement and reconciliation processes.
Research Question
Whether, on average, being directly injured or maimed in this episode made individuals more likely to feel “vengeful” and unwilling to make peace with those who perpetrated this violence. Or, were those who directly suffered from such violence most motivated to see it end by making peace?
Model Specification
\[
\begin{aligned}
peacefactor = \beta_0 & + \beta_1 directlyharmed
+ \beta_2 female + \beta_3 village \\
& + \beta_4 age + \beta_5 farmerdar + \beta_6 herderdar \\
& + \beta_7 pastvoted + \beta_8 hhsizedarfur + \epsilon
\end{aligned}
\] where, \(peacefactor\) is the outcome, \(directlyharmed\) is the treatment of interest, and rest are observed controls.
#install.packages("sensemakr")library(sensemakr)# load data from packagesdata("darfur")# runs regression modeldarfur.model <-lm(peacefactor ~ directlyharmed +# DV and Treatment female + village +# Confounders Observed age + farmer_dar + herder_dar + pastvoted + hhsize_darfur, # Other Controlsdata = darfur)#summary(darfur.model) # Shows whole result with Village FEdarfur.model$coefficients[1:3] # Just the intercept, treatment, one observed covariate
To make causal claim, we have to assume that above model completely identifies the process. That is, there is no unobserved confounding causing any bias. But as most cases that is a big sell, particularly in observational studies.
Three possible confounders unobserved are location of bombing (center), wealth of individuals (wealth) and political ideology (political_attitudes).
Think
How are they possible confounders?
Additonally, all these factors could interact with each other or otherwise have non-linear effects.
So, in an ideal world, we would want to run the following model: \[
\begin{aligned}
peacefactor = \beta_0 & + \beta_1 directlyharmed + \beta_2 village + \beta_3 female \\
& + \beta_4 age + \beta_5 farmerDar + \beta_6 herderDar + \beta_7 pastvoted \\
& + \beta_8 hhsizeDarfur + \beta_9 center + \beta_{10} wealth + \beta_{11} politicalAttitudes \\
& + \beta_{12} (center * wealth) + \beta_{13} (center * politicalAttitudes) \\
& + \beta_{14} (wealth * politicalAttitudes) + \beta_{15} (center * wealth * politicalAttitudes) + \epsilon
\end{aligned}
\]
Equivalent R code:
darfur.complete.model <-lm(peacefactor ~ directlyharmed + village + female + age + farmer_dar + herder_dar + pastvoted +hhsize_darfur + center*wealth*political_attitudes, data = darfur)# Just BTW, why is eval = FALSE in the code chunk header?
But we will get an error, as those measures are not there in data - because they were never measured.
Omitted Variable Bias is lurking!
However, recalling the idea from start of the class, we can estimate how much these or all unobserved confounders can affect our result/conclusions.
“Or, more precisely, given an assumption on how strongly these and other omitted variables relate to the treatment and the outcome, how would including them have changed our inferences regarding the coefficient of directlyharmed?” - Cinelli and Hazlett (2020)
Using sensemakr package
The following text is from online vignette of sensemaker package as they explain it in very clear terms.
# runs sensemakr for sensitivity analysis# in the darfur exampledarfur.sensitivity <-sensemakr(model = darfur.model, treatment ="directlyharmed",benchmark_covariates ="female",kd =1:3,ky =1:3, q =1,alpha =0.05, reduce =TRUE)
The arguments are:
model: the lm object with the outcome regression. In our case, darfur.model.
treatment: the name of the treatment variable. In our case, "directlyharmed".
benchmark_covariates: the names of covariates that will be used to bound the plausible strength of the unobserved confounders. Here, we put "female", which we argue to be among the main determinants of exposure to violence and find to be a strong determinant of attitudes towards peace.
kd and ky: these arguments parameterize how many times stronger the confounder is related to the treatment (kd) and to the outcome (ky) in comparison to the observed benchmark covariate (female). In our example, setting kd = 1:3 and ky = 1:3 means we want to investigate the maximum strength of a confounder once, twice, or three times as strong as female (in explaining treatment and outcome variation). If only kd is given, ky will be set equal to it by default.
q: this allows the user to specify what fraction of the effect estimate would have to be explained away to be problematic. Setting q = 1, as we do here, means that a reduction of 100% of the current effect estimate, that is, a true effect of zero, would be deemed problematic. The default is 1.
alpha: significance level of interest for making statistical inferences. The default is 0.05.
reduce: should we consider confounders acting towards increasing or reducing the absolute value of the estimate? The default is reduce = TRUE, which means we are considering confounders that pull the estimate towards (or through) zero.
# Simpler run of the codedarfur.sensitivity <-sensemakr(model = darfur.model, treatment ="directlyharmed",benchmark_covariates ="female",kd =1:3)# printing the result in consoledarfur.sensitivity
Sensitivity Analysis to Unobserved Confounding
Model Formula: peacefactor ~ directlyharmed + female + village + age + farmer_dar +
herder_dar + pastvoted + hhsize_darfur
Null hypothesis: q = 1 and reduce = TRUE
Unadjusted Estimates of ' directlyharmed ':
Coef. estimate: 0.09732
Standard Error: 0.02326
t-value: 4.18445
Sensitivity Statistics:
Partial R2 of treatment with outcome: 0.02187
Robustness Value, q = 1 : 0.13878
Robustness Value, q = 1 alpha = 0.05 : 0.07626
For more information, check summary.
The print method of sensemakr provides a quick review of the original (unadjusted) estimate along with three summary sensitivity statistics suited for routine reporting: the partial \(R^2\) of the treatment with the outcome, the robustness value (RV) required to reduce the estimate entirely to zero (i.e. \(q=1\)), and the RV beyond which the estimate would no longer be statistically distinguishable from zero at the 0.05 level (\(q=1\), \(\alpha=0.05\)).
# Latex and HTML resultsovb_minimal_reporting(darfur.sensitivity, format ="html")
#ovb_minimal_reporting(darfur.sensitivity, format = "html")# summary(darfur.sensitivity) #Verbose summary
These three sensitivity statistics provide a minimal reporting for sensitivity analysis. More precisely:
The robustness value for bringing the point estimate of directlyharmed exactly to zero (\(RV_{q=1}\)) is 13.9% . This means that unobserved confounders that explain 13.9% of the residual variance both of the treatment and of the outcome are sufficiently strong to explain away all the observed effect. On the other hand, unobserved confounders that do not explain at least 13.9% of the residual variance both of the treatment and of the outcome are not sufficiently strong to do so.
The robustness value for testing the null hypothesis that the coefficient of directlyharmed is zero \((RV_{q =1, \alpha = 0.05})\) falls to 7.6%. This means that unobserved confounders that explain 7.6% of the residual variance both of the treatment and of the outcome are sufficiently strong to bring the lower bound of the confidence interval to zero (at the chosen significance level of 5%). On the other hand, unobserved confounders that do not explain at least 7.6% of the residual variance both of the treatment and of the outcome are not sufficiently strong to do so.
Finally, the partial \(R^2\) of directlyharmed with peacefactor means that, in an extreme scenario, in which we assume that unobserved confounders explain all of the left out variance of the outcome, these unobserved confounders would need to explain at least 2.2% of the residual variance of the treatment to fully explain away the observed effect.
These are useful quantities that summarize what we need to know in order to safely rule out confounders that are deemed to be problematic. Interpreting these values requires domain knowledge about the data generating process. Therefore, we encourage researchers to argue about what are plausible bounds on the maximum explanatory power that unobserved confounders could have in a given application.
Sometimes researchers may have a hard time making judgments regarding the absolute strength of a confounder, but may have grounds to make relative claims, for instance, by arguing that unobserved confounders are likely not multiple times stronger than a certain observed covariate. In our application, this is indeed the case. One could argue that, given the nature of the attacks, it is hard to imagine that unobserved confounding could explain much more of targeting than what was explained by the observed variable female.
The lower corner of the table, thus, provides bounds on confounding as strong as female, \(R^2_{Y\sim Z| {\bf X}, D}\) = 12.5%, and \(R^2_{D\sim Z| {\bf X} }\) = 0.9%. Since both of those are below the RV, the table reveals that confounders as strong as female are not sufficient to explain away the observed estimate.
Moreover, the bound on \(R^2_{D\sim Z| {\bf X} }\) is below the partial \(R^2\) of the treatment with the outcome, \(R^2_{Y \sim D |{\bf X}}\). This means that even an extreme confounder explaining all residual variation of the outcome and as strongly associated with the treatment as female would not be able to overturn the research conclusions.
These results are exact for a single unobserved confounder, and conservative for multiple confounders, possibly acting non-linearly. Finally, the summary method for sensemakr provides an extensive report with verbal descriptions of all these analyses. Here, for instance, entering summary(darfur.sensitivity) produces verbose output similar to the text explanations in the last several paragraphs, so that researchers can directly cite or include such text in their reports.
Sensitivity contour plots of point estimates and t-values
The previous sensitivity table provides a good summary of how robust the current estimate is to unobserved confounding. However, researchers may be willing to refine their analysis by visually exploring the whole range of possible estimates that confounders with different strengths could cause. For these, one can use the plot method for sensemakr.
Sensitivity contour plots?
Sensitivity contour plots are graphical tools that visually represent the sensitivity of point estimates and t-values to varying levels of unobserved confounding. They help to visualize the potential impact of different types of confounders on the study results.
We begin by examining the default plot type, contour plots for the point estimate.
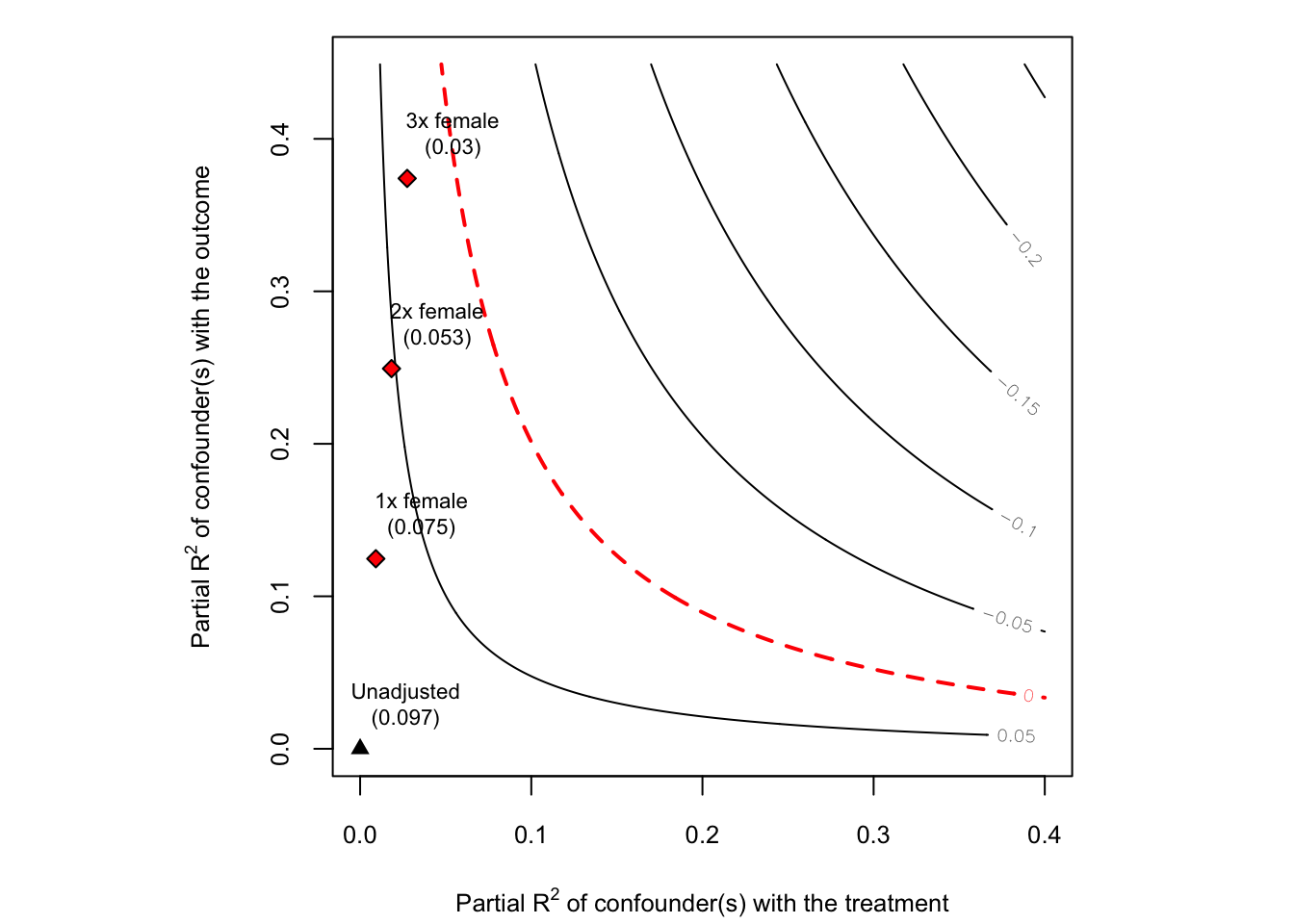
plot(darfur.sensitivity)
The horizontal axis shows the hypothetical residual share of variation of the treatment that unobserved confounding explains, \(R^2_{D\sim Z| {\bf X} }\). The vertical axis shows the hypothetical partial \(R^2\) of unobserved confounding with the outcome, \(R^2_{Y\sim Z| {\bf X}, D}\). The contours show what would be the estimate for directlyharmed that one would have obtained in the full regression model including unobserved confounders with such hypothetical strengths. Note the plot is parameterized in way that hurts our preferred hypothesis, by pulling the estimate towards zero—the direction of the bias was set in the argument reduce = TRUE of sensemakr().
The bounds on the strength of confounding, determined by the parameter kd = 1:3 in the call for sensemakr(), are also shown in the plot. Note that the plot reveals that the direction of the effect (positive) is robust to confounding once, twice or even three times as strong as the observed covariate female, although in this last case the magnitude of the effect is reduced to a third of the original estimate.
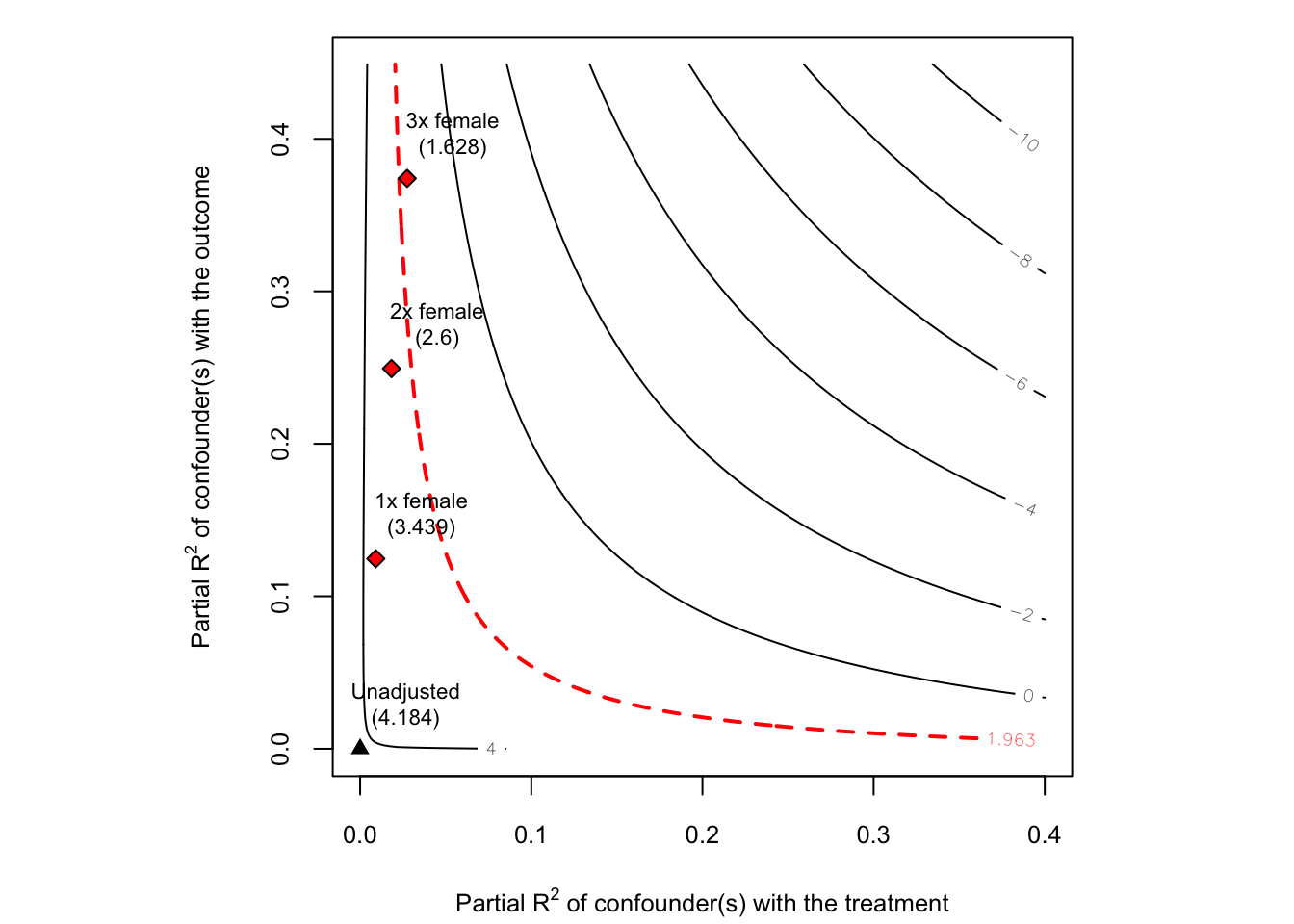
We now examine the sensitivity of the t-value for testing the null hypothesis of zero effect. For this, it suffices to change the option sensitivity.of = "t-value".
The plot reveals that, at the 5% significance level, the null hypothesis of zero effect would still be rejected given confounders once or twice as strong as female. However, by contrast to the point-estimate, accounting for sampling uncertainty now means that the null hypothesis of zero effect would not be rejected with the inclusion of a confounder three times as strong as female.
Sensitivity plots of extreme scenarios
Sometimes researchers may be better equipped to make plausibility judgments about the strength of determinants of the treatment assignment mechanism, and have less knowledge about the determinants of the outcome. In those cases, sensitivity plots using extreme scenarios are a useful option. These are produced with the option type = extreme. Here one assumes confounding explains all or some large fraction of the residual variance of the outcome, then vary how strongly such confounding is hypothetically related to the treatment, to see how this affects the resulting point estimate.
Extreme scenario sensitivity plots
Extreme scenario sensitivity plots examine the sensitivity of the estimated effect under the conservative assumption that all or a large portion of the unexplained variance in the outcome is due to confounding. These plots help to explore the worst-case scenarios in terms of unobserved confounding.
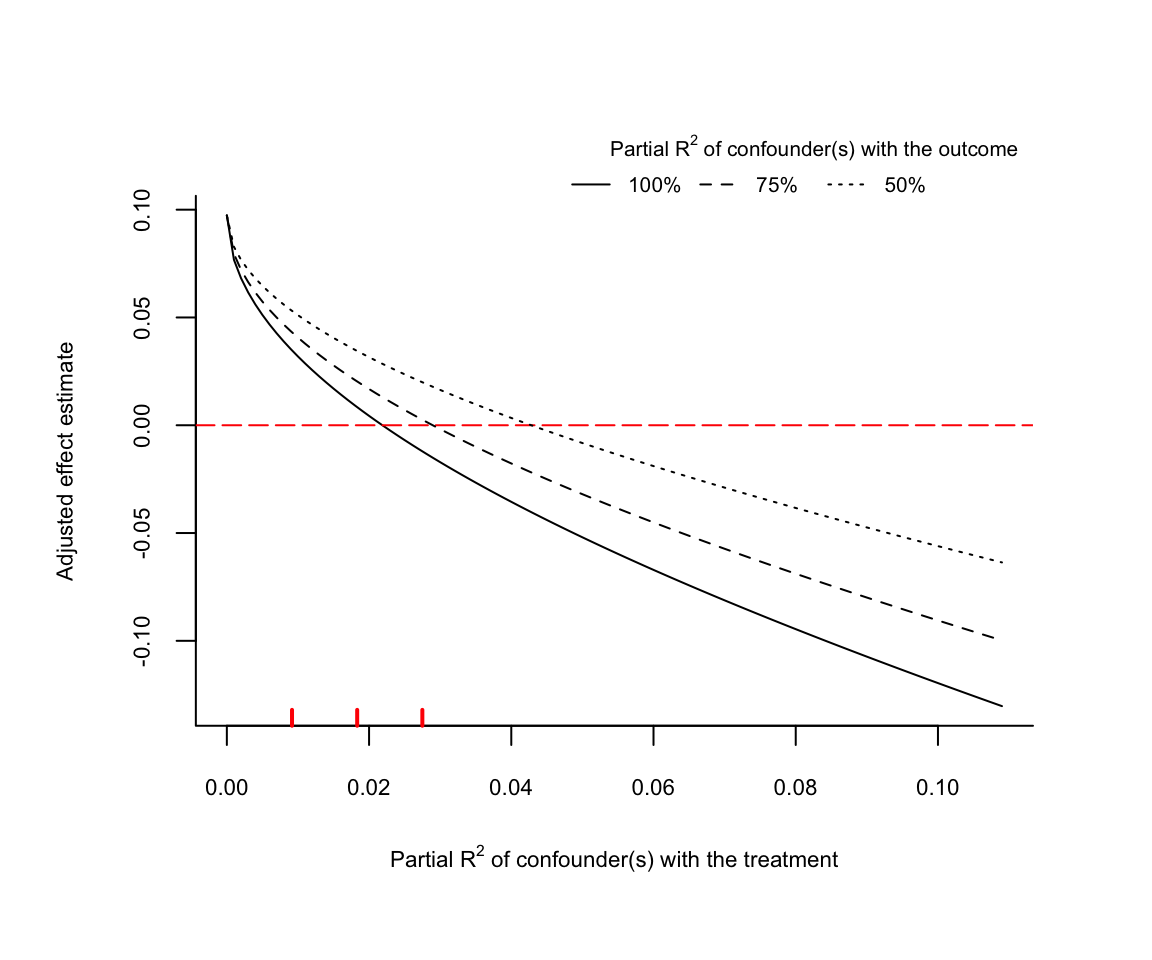
plot(darfur.sensitivity, type ="extreme")
The default option for the extreme scenarios is r2yz.dx = c(1, 0.75, 0.5), which sets the association of confounders with the outcome to \(R^2_{Y \sim Z | X, D} = 100\%\), \(R^2_{Y \sim Z | X, D} = 75\%\), and \(R^2_{Y \sim Z | X, D} = 50\%\) (producing three separate curves). The bounds on the strength of association of a confounder being once, twice, or three times as strongly associated with the treatment as the effect of being female are shown as red ticks on the horizontal axis.
As the plot shows, even in the most extreme case of \(R^2_{Y \sim Z | X, D} = 100\%\), confounders would need to be more than twice as strongly associated with the treatment to fully explain away the point estimate. Moving to the scenarios \(R^2_{Y \sim Z | X, D} = 75\%\) and \(R^2_{Y \sim Z | X, D} = 50\%\), confounders would need to be more than three times as strongly associated with the treatment as the effect of being female in order to fully explain away the point estimate.
Mediation analysis aims to explain the causal relationship between a treatment variable and an outcome variable by examining the intermediating mediatior variable. That is, it is a way to understand possible causal mechanism. It’s the “how” and “why” behind a cause-and-effect relationship.
Mediation analysis uses Sequential Ignorability which is a crucial assumption for identifying causal mechanisms. Formally,
\(Eq.1\) Treatment assignment is ignorable: Given pre-treatment confounders, the treatment is statistically independent of potential outcomes and mediators. This is similar to the “no omitted variable bias” assumption in causal effect estimation.
\(Eq.2\)Mediator is ignorable: Given treatment status and pre-treatment confounders, the mediator is statistically independent of potential outcomes.
The second assumption is a particularly strict assumption as it seeks to assume that there is a complete absence of any post as well and pre-treatment confounders (both measured and unmeasured).
This assumption allows us to estimate the counterfactual outcomes we need to calculate the effects of the mediator, even though we cannot observe them directly.
Conceptually, mediation is understood by decomposing the total causal effect of a treatment on an outcome into the indirect effect (through the mediator) and the direct effect (all other causal pathways). The indirect effect is also known as the causal mediation effect.
Decomposed effects
Average Causal Mediation Effect (ACME): The average change in the outcome variable that would occur if the mediator were changed from the value it would take under the control condition to the value it would take under the treatment condition, while holding the treatment variable constant.
Average Direct Effect (ADE): The average change in the outcome variable that would occur due to the treatment, independent of any effect mediated through the mediator variable.
How to do mediation analysis
Model mediator as function of \(Tr\) and \(X\)s.
Model outcome as function of \(Mediator\), \(Tr\), and \(Xs\).
Based on (1) produce two set of prediction values of mediators for \(Tr =1\) and \(Tr = 0\).
Make outcome predictions from (2).
Outcome predicted under treatment using predicted mediator values under \(Tr=1\).
Outcome predicted under treatment, now using predicted mediator values under \(Tr=0\).
ACME is calculated using average difference between the above two.
Refer to Tingley et al. (2014) for thorough details of the code below. The details of the mediation analysis on framing experiment used as an example here is explained in Imai et al. (2011) and the original framing experiment is from the paper by Brader, Valentino, and Suhay (2008) .
Paper:
Brader, T., Valentino, N. A., & Suhay, E. (2008). What Triggers Public Opposition to Immigration? Anxiety, Group Cues, and Immigration Threat. American Journal of Political Science, 52(4), 959–978. https://www.jstor.org/stable/25193860
Abstract:
We examine whether and how elite discourse shapes mass opinion and action on immigration policy. One popular but untested suspicion is that reactions to news about the costs of immigration depend upon who the immigrants are. We confirm this suspicion in a nationally representative experiment: news about the costs of immigration boosts white opposition far more when Latino immigrants, rather than European immigrants, are featured. We find these group cues influence opinion and political action by triggering emotions-in particular, anxiety-not simply by changing beliefs about the severity of the immigration problem. A second experiment replicates these findings but also confirms their sensitivity to the stereotypic consistency of group cues and their context. While these results echo recent insights about the power of anxiety, they also suggest the public is susceptible to error and manipulation when group cues trigger anxiety independently of the actual threat posed by the group.
Exploratory Data Analysis
library(mediation)# data data("framing", package ="mediation")# codebook for dataset # ?framing# treat - product of two treatment variables. Equal to one when the story focuses on costs and features Latino immigrantsggplot(framing, aes(x =as.factor(treat))) +geom_bar(fill ="steelblue", color ="black") +labs(x ="Treatment", y ="Count", title ="Histogram of Treatment Groups") +theme_minimal()
# mediator - lower scores equal more negative emotionggplot(framing, aes(x =emo)) +geom_bar(fill ="steelblue", color ="black") +labs(x ="Mediator", y ="Count", title ="Mediator Distribution") +theme_minimal()
# outcome - whether the subjects requested anti-immigration message to Congress on their behalfggplot(framing, aes(x =as.factor(cong_mesg))) +geom_bar(fill ="steelblue", color ="black") +labs(x ="Outcome", y ="Count", title ="Outcome Distribution") +theme_minimal()
# table of anxiousness about increased immigration vs. emotional scale mediator during experiment | See codebookkable(table(framing$anx, framing$emo))
3
4
5
6
7
8
9
10
11
12
not asked
0
0
0
0
0
0
0
0
0
0
refused
0
0
0
0
0
0
0
0
0
0
very anxious
35
15
7
1
1
0
1
0
0
0
somewhat anxious
0
8
27
26
15
6
3
1
0
0
a little anxious
0
0
2
2
20
19
14
12
5
0
not anxious at all
0
0
0
0
0
1
4
8
10
22
Using mediation package
# naive model - using linear probability modelbase.fit <-lm(cong_mesg ~ treat + age + educ + gender + income, data = framing)modelsummary(base.fit)
(1)
(Intercept)
0.295
(0.160)
treat
0.105
(0.065)
age
0.002
(0.002)
educhigh school
-0.132
(0.115)
educsome college
-0.293
(0.120)
educbachelor's degree or higher
-0.299
(0.119)
genderfemale
-0.123
(0.057)
income
0.020
(0.008)
Num.Obs.
265
R2
0.081
R2 Adj.
0.056
AIC
348.5
BIC
380.7
Log.Lik.
-165.262
F
3.243
RMSE
0.45
#using linear fit to estimate the effect of treatment on the mediator | Mediatormed.fit <-lm(emo ~ treat + age + educ + gender + income, data = framing)modelsummary(med.fit)
(1)
(Intercept)
8.672
(0.885)
treat
1.339
(0.360)
age
0.002
(0.010)
educhigh school
-1.041
(0.634)
educsome college
-1.813
(0.664)
educbachelor's degree or higher
-3.047
(0.660)
genderfemale
0.070
(0.314)
income
-0.035
(0.042)
Num.Obs.
265
R2
0.190
R2 Adj.
0.168
AIC
1254.2
BIC
1286.5
Log.Lik.
-618.123
F
8.590
RMSE
2.49
#using probit to estimate the effect of the mediator on the outcome | Outcomeout.fit <-glm(cong_mesg ~ emo + treat + age + educ + gender + income, data = framing, family =binomial("probit"))modelsummary(out.fit)
(1)
(Intercept)
-2.608
(0.609)
emo
0.206
(0.036)
treat
0.040
(0.202)
age
0.006
(0.006)
educhigh school
-0.197
(0.337)
educsome college
-0.590
(0.363)
educbachelor's degree or higher
-0.367
(0.370)
genderfemale
-0.396
(0.175)
income
0.084
(0.026)
Num.Obs.
265
AIC
297.3
BIC
329.5
Log.Lik.
-139.652
F
6.069
RMSE
0.42
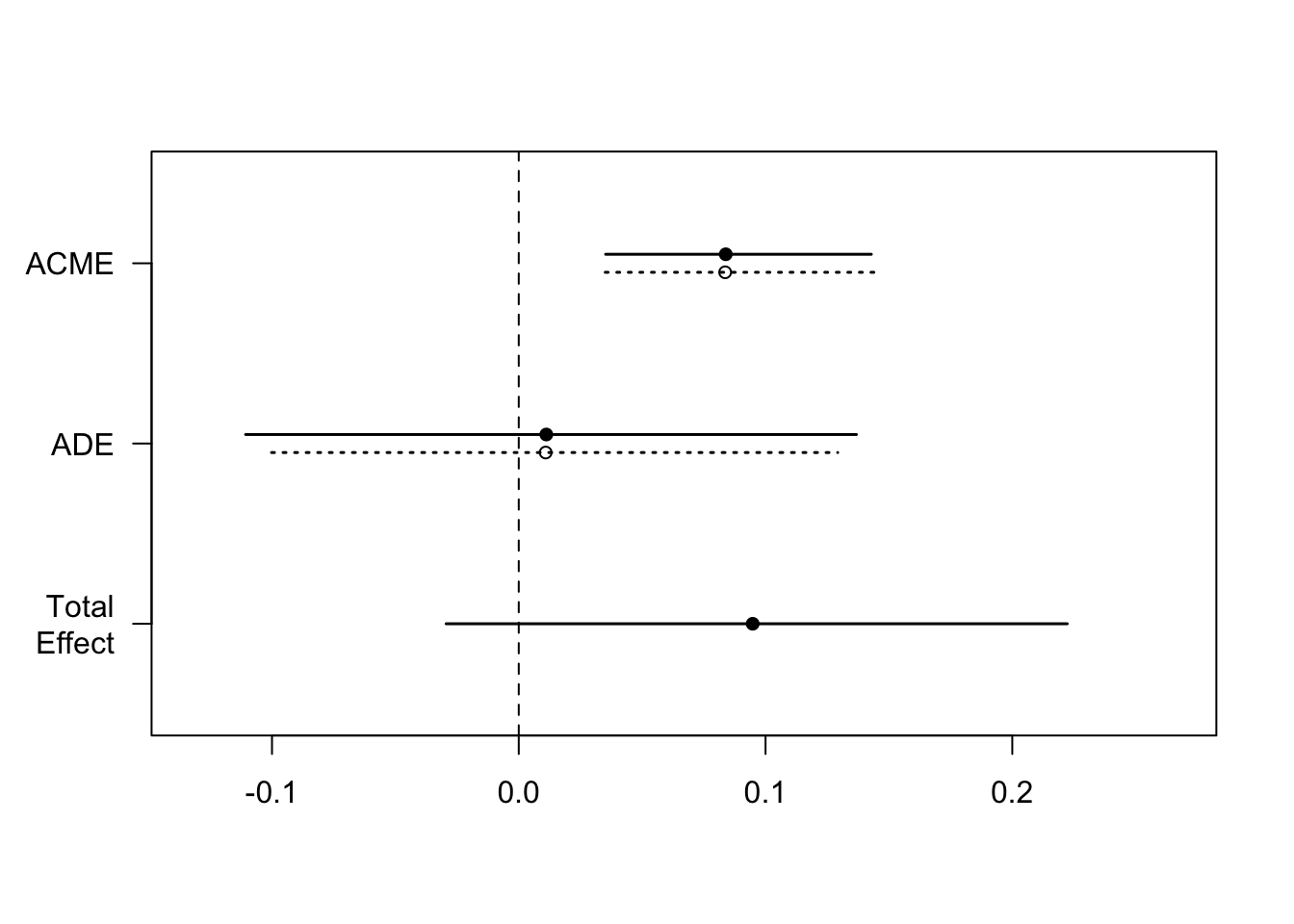
#we estimate ACME and ADE using the mediate functionmed.out <-mediate(med.fit, out.fit, treat ="treat", mediator ="emo", robustSE =TRUE, sims =1000)summary(med.out)
# See the details of function#?mediate# plot plot(med.out)
In this example, the estimated ACMEs are statistically significantly different from zero but the estimated average direct and total effects are not. The results suggest that the treatment in the framing experiment may have increased emotional response, which in turn made subjects more likely to send a message to his or her member of Congress. Here, since the outcome is binary all estimated effects are expressed as the increase in probability that the subject sent a message to his or her Congress person.
Interaction between the treatment and the mediator
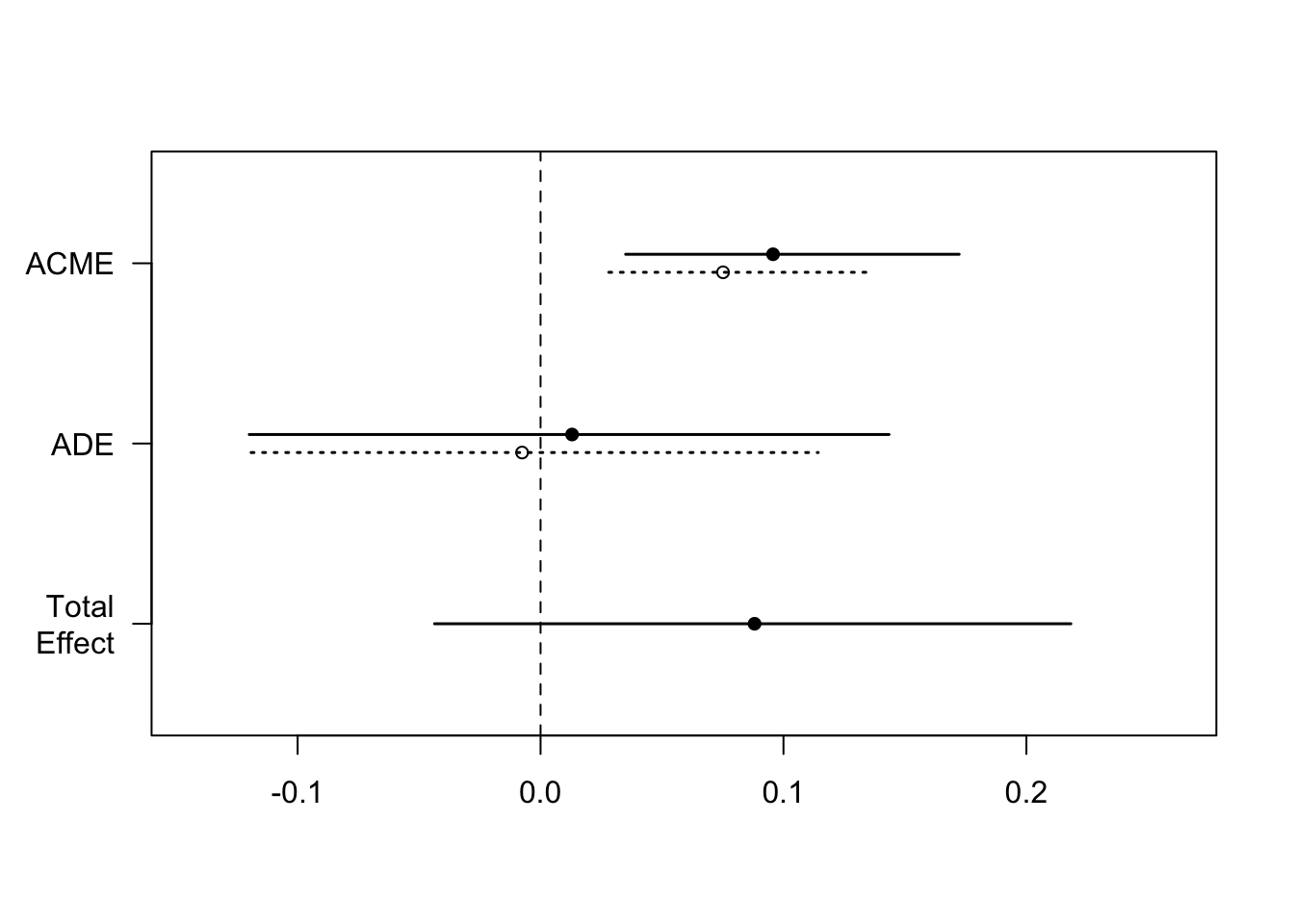
It is possible that the ACME takes different values depending on the baseline treatment status. In such a situation, we can add an interaction term between the treatment and mediator to the outcome model.
#treatment and mediator interactionset.seed(2014)#the estimated ACME varies with treatment statusmed.fit <-lm(emo ~ treat + age + educ + gender + income, data = framing)out.fit <-glm(cong_mesg ~ emo * treat + age + educ + gender + income, data = framing, family =binomial("probit")) # adding interaction heremed.out <-mediate(med.fit, out.fit, treat ="treat", mediator ="emo", robustSE =TRUE, sims =1000)# summary with interaction summary(med.out)
#testing for the significance of the treatment-mediator interactiontest.TMint(med.out, conf.level = .95)
Test of ACME(1) - ACME(0) = 0
data: estimates from med.out
ACME(1) - ACME(0) = 0.020577, p-value = 0.358
alternative hypothesis: true ACME(1) - ACME(0) is not equal to 0
95 percent confidence interval:
-0.03019934 0.07454068
Sensitivity analysis for sequential ignorability.
Recall \(\rho\) i.e. the covariance between \(\epsilon_{i2}\) and \(\epsilon_{i3}\) from class slides. It forms a strong assumption in the traditonally followed Linear Structural Equation Modelling Method (LSEM) of determining mediation.
More detailed discussion in the section Sensitivity Analysis in Imai et al. (2011, pp 774):
“Imai, Keele, and Tingley (2010) and Imai, Keele, and Yamamoto (2010) propose a sensitivity analysis based on the correlation between \(\epsilon_{i2}\), the error for the mediation model, and \(\epsilon_{i3}\) , the error for the outcome model, under a standard LSEM setting and several commonly used nonlinear models. They use ρ to denote the correlation across the two error terms. If sequential ignorability holds, all relevant pretreatment confounders have been conditioned on, and thus ρ equals zero. However, nonzero values of ρ imply departures from the sequential ignorability assumption and that some hidden confounder is biasing the ACME estimate.”.
#sensitivity analysis for sequential ignorabilitymed.fit <-lm(emo ~ treat + age + educ + gender + income, data = framing)out.fit <-glm(cong_mesg ~ emo + treat + age + educ + gender + income, data = framing, family =binomial("probit"))med.out <-mediate(med.fit, out.fit, treat ="treat", mediator ="emo", robustSE =TRUE, sims =1000)sens.out <-medsens(med.out, rho.by =0.1, effect.type ="indirect", sims =1000)
Warning in rho^2 * (1 - r.sq.m) * (1 - r.sq.y): Recycling array of length 1 in vector-array arithmetic is deprecated.
Use c() or as.vector() instead.
Warning in err.cr.d^2 * (1 - r.sq.m) * (1 - r.sq.y): Recycling array of length 1 in vector-array arithmetic is deprecated.
Use c() or as.vector() instead.
summary(sens.out)
Mediation Sensitivity Analysis: Average Mediation Effect
Sensitivity Region: ACME for Control Group
Rho ACME(control) 95% CI Lower 95% CI Upper R^2_M*R^2_Y* R^2_M~R^2_Y~
[1,] 0.3 0.0055 -0.0076 0.0172 0.09 0.0493
[2,] 0.4 -0.0094 -0.0265 0.0020 0.16 0.0877
Rho at which ACME for Control Group = 0: 0.3
R^2_M*R^2_Y* at which ACME for Control Group = 0: 0.09
R^2_M~R^2_Y~ at which ACME for Control Group = 0: 0.0493
Sensitivity Region: ACME for Treatment Group
Rho ACME(treated) 95% CI Lower 95% CI Upper R^2_M*R^2_Y* R^2_M~R^2_Y~
[1,] 0.3 0.0064 -0.0086 0.020 0.09 0.0493
[2,] 0.4 -0.0113 -0.0319 0.002 0.16 0.0877
Rho at which ACME for Treatment Group = 0: 0.3
R^2_M*R^2_Y* at which ACME for Treatment Group = 0: 0.09
R^2_M~R^2_Y~ at which ACME for Treatment Group = 0: 0.0493
here rho.by = 0.1 specifies that ρ will vary from −0.9 to 0.9 by 0.1 increments, and effect.type = “indirect” means that sensitivity analysis is conducted for the ACME. Alternatively, specifying effect.type = “direct” performs sensitivity analysis for the ADE and “both” returns sensitivity analysis for the ACME and ADE.
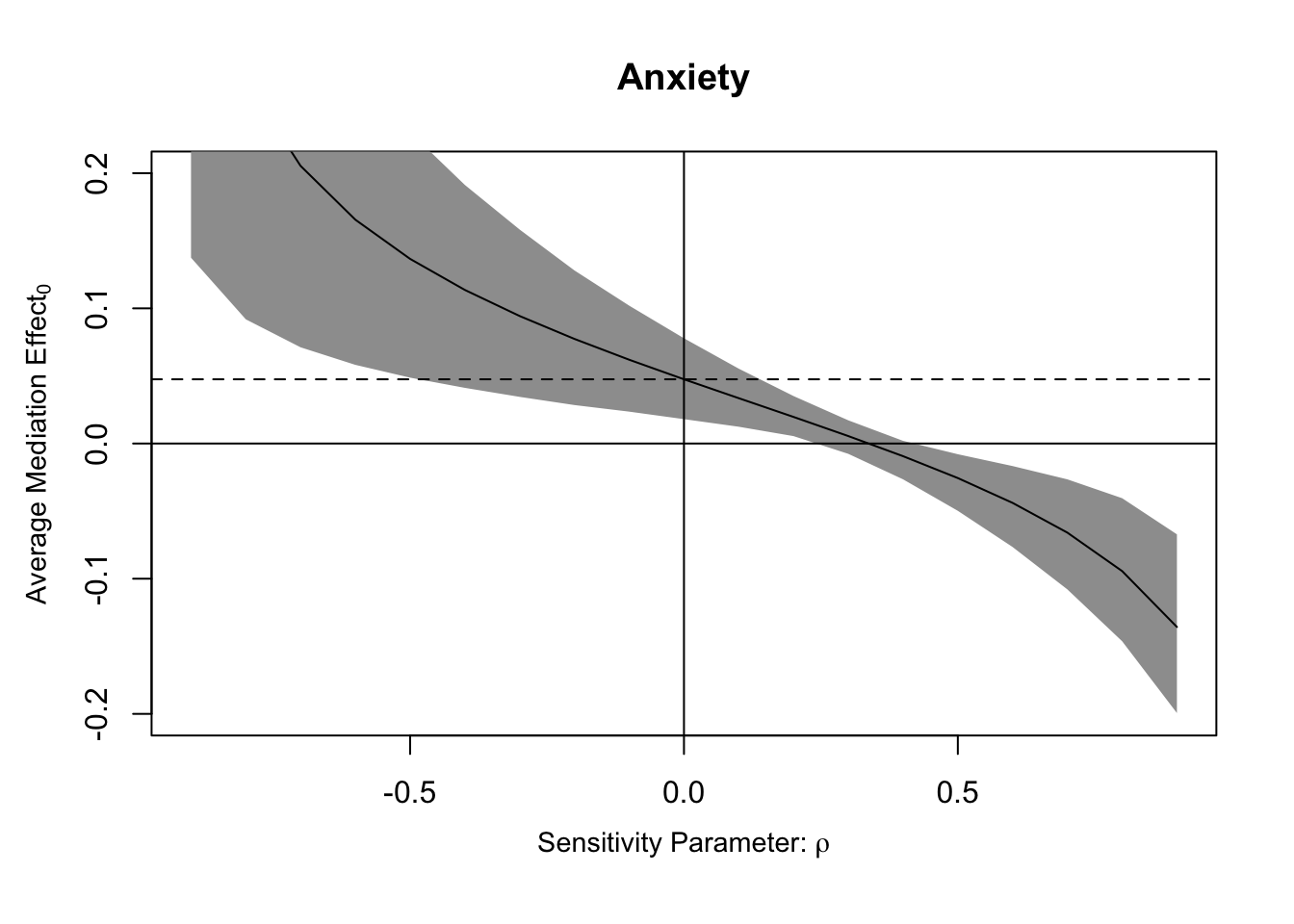
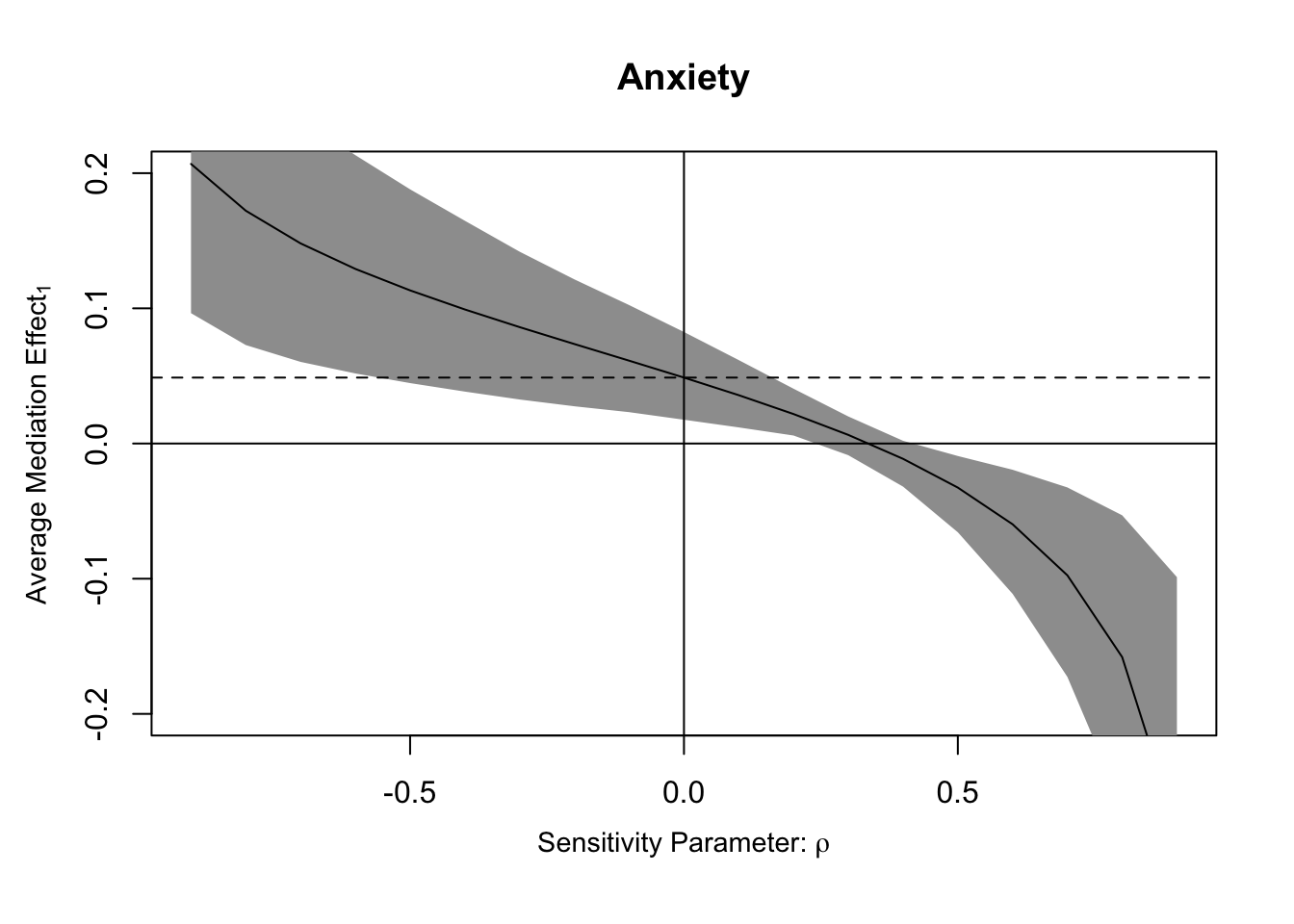
The tabular output from the summary function displays the values of ρ at which the confidence intervals contain zero for the ACME. For both the control and treatment conditions, the confidence intervals for the ACME contain zero when ρ equals 0.3 and 0.4.
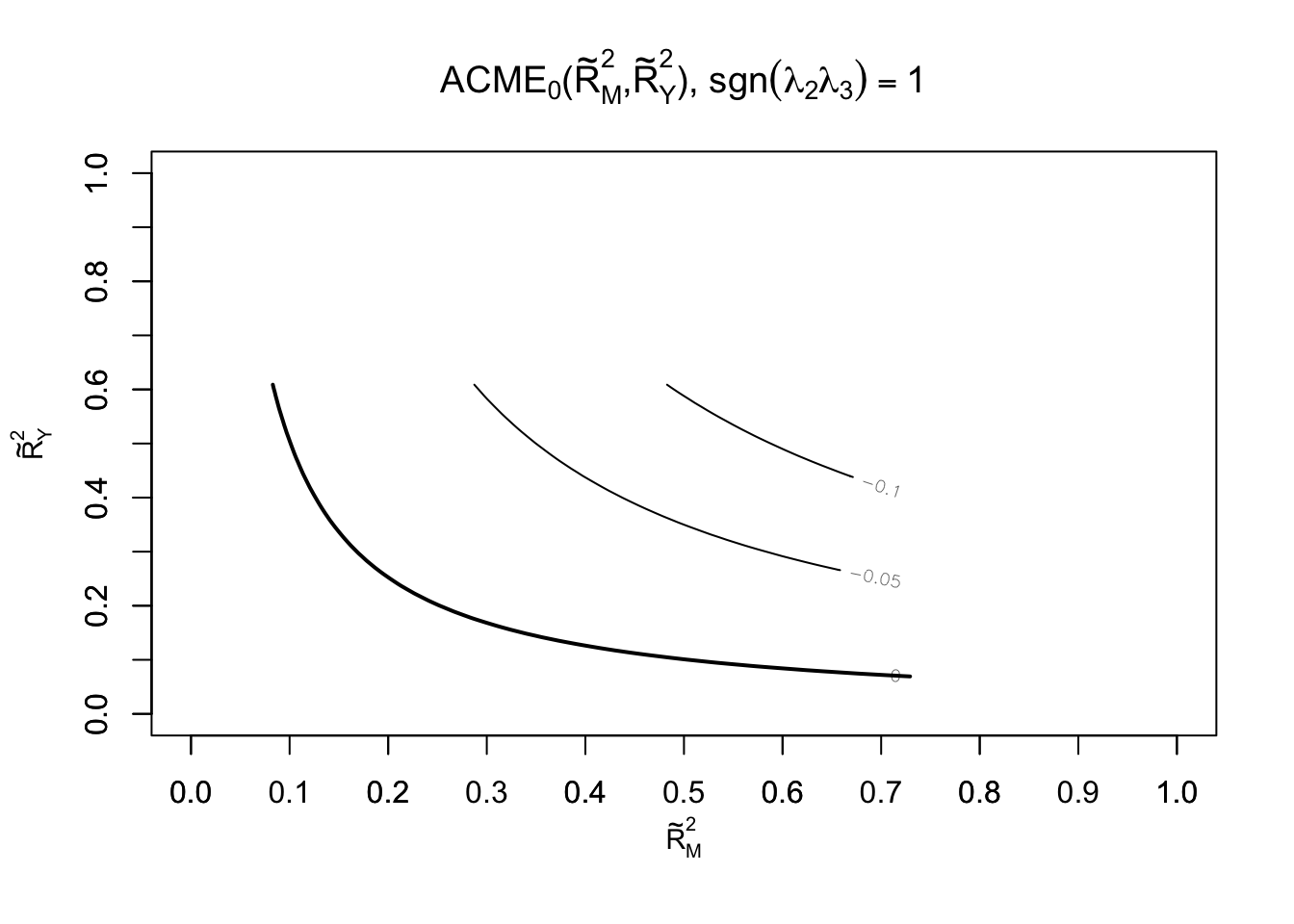
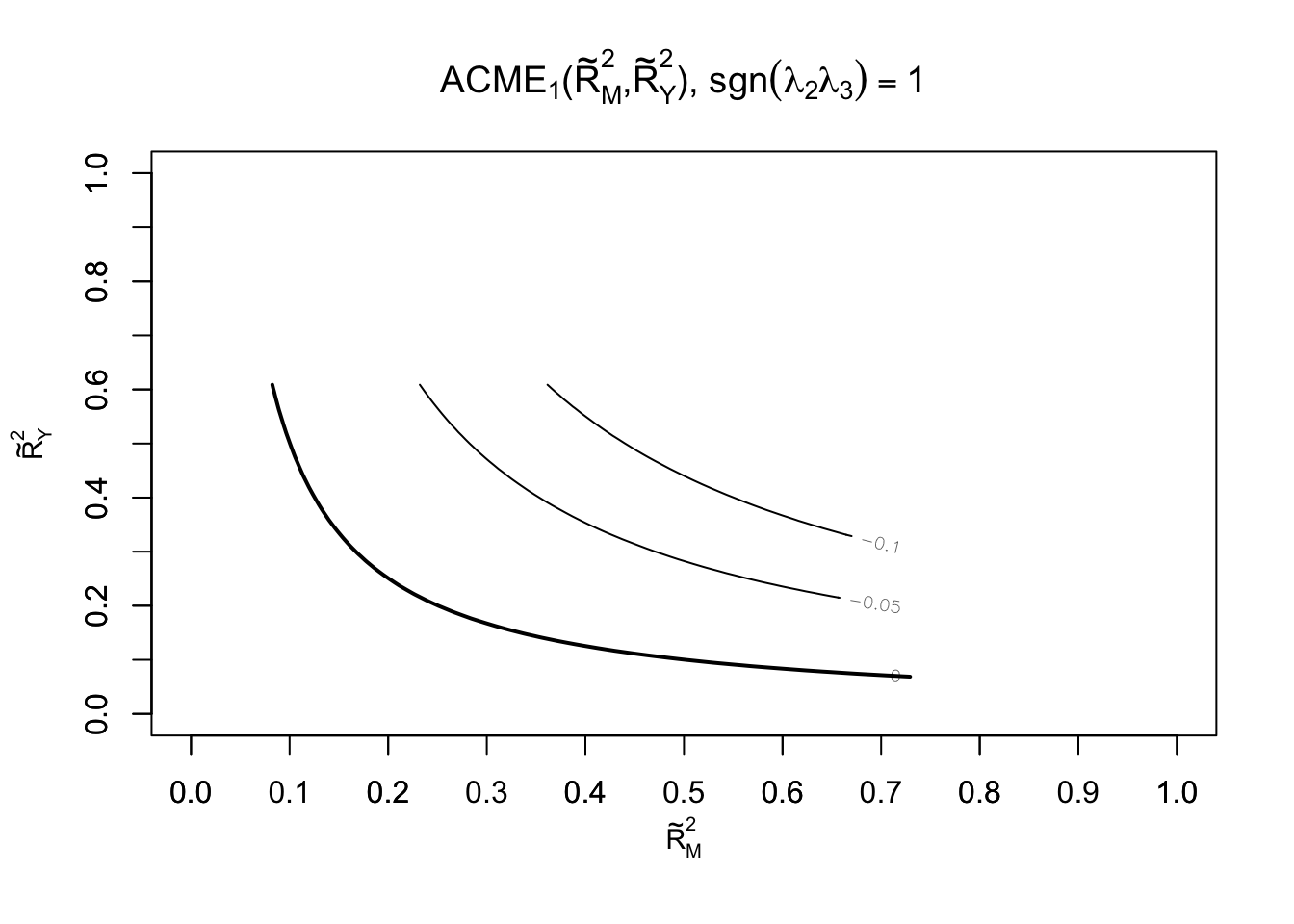
In the last section of tabular output, the first row captures the point at which the ACME is 0 as a function of the proportions of residual variance in the mediator and outcome explained by the hypothesized unobserved confounder. The second line uses the total variance instead of residual variance.
#plotting sensitivity#as a function of rhoplot(sens.out, sens.par ="rho", main ="Anxiety", ylim =c(-0.2, 0.2))
#as a function of R2plot(sens.out, sens.par ="R2", r.type ="total", sign.prod ="positive")
Warning in (1 - x$r.square.y) * seq(0, 1 - x$rho.by, 0.01): Recycling array of length 1 in array-vector arithmetic is deprecated.
Use c() or as.vector() instead.
When using the R2 statistic version of sensitivity analysis the user must specify whether the hypothesized confounder affects the mediator and outcome variables in the same direction or in different directions. This matters because the sensitivity analysis is in terms of the product of R2 statistics. In the current example, it is assumed that the confounder influences both variables in the same direction by setting sign.prod = “positive” (rather than sign.prod = “negative”).
Substantive interpretation of the plots in Imai et al. (2011, pp 776).
Glossary and Additional Notes
Sensitivity Analysis
Sensitivity by OVB perspective
Sensitivity for Instrumental Variable Regressions
Omitted Variable Bias (OVB): The bias in the estimate of a treatment effect that arises when a variable that is correlated with both the treatment and the outcome is not included in the regression model.
Sensitivity Analysis: A technique used to assess the robustness of research findings to the potential influence of unobserved confounders. It involves examining how the results would change under different assumptions about the strength and nature of these confounders.
Partial R2: A statistical measure indicating the proportion of variance in the dependent variable uniquely explained by a specific independent variable, after controlling for other variables in the model.
Robustness Value (RV): A sensitivity measure developed by Cinelli and Hazlett (2020) that represents the minimum strength of association an unobserved confounder needs to have with both the treatment and outcome to change the study conclusions.
R2Y∼D|X: The partial R2 of the treatment with the outcome, representing the proportion of outcome variation uniquely explained by the treatment assignment.
Benchmarking: A method used in sensitivity analysis to gauge the plausible strength of unobserved confounders by comparing them to observed covariates.
Informal Benchmarking: A problematic approach to benchmarking where researchers use the observed statistics of an included covariate to speculate about the characteristics of the omitted variable. This can lead to inaccurate assessments of sensitivity due to the potential influence of the omitted variable on the observed covariate.
Bounding the Strength of Confounders: A technique proposed by Cinelli and Hazlett (2020) where researchers formally compare the explanatory power of an unobserved confounder to that of an observed covariate. This allows for establishing plausible limits on the potential influence of the unobserved confounder.
Extreme Scenario Sensitivity Analysis: An analysis where researchers consider the maximum possible strength of association an unobserved confounder could have with the outcome. This usually involves assuming the unobserved confounder explains all residual variation in the outcome.
Sensitivity Contour Plots: Graphical tools that visually display how point estimates, t-values, or other statistics change under different assumptions about the strength of association between the unobserved confounder and the treatment and outcome. These plots help visualize the sensitivity of the results to various confounding scenarios.
Bias Factor (BF): In the partial R2 parameterization, the BF quantifies the degree to which the treatment effect estimate is biased due to an unobserved confounder. It is calculated using the partial R2 values representing the associations between the confounder and the treatment and the confounder and the outcome.
Mediation Analysis
Average Causal Mediation Effect (ACME): The average change in the outcome variable that would occur if the mediator were changed from the value it would take under the control condition to the value it would take under the treatment condition, while holding the treatment variable constant.
Average Direct Effect (ADE): The average change in the outcome variable that would occur due to the treatment, independent of any effect mediated through the mediator variable.
Causal Mechanism: The process by which a treatment variable influences an outcome variable, often involving intermediate variables or mediators.
Complier Average Mediation Effect (CACME): The ACME for the subset of individuals who comply with the encouragement in an encouragement design.
Encouragement Design: A research design where an encouragement variable is randomized to influence the mediator, allowing researchers to estimate the causal effect of the mediator on the outcome.
Mediator Variable: A variable that lies on the causal pathway between the treatment and outcome variables, representing the mechanism through which the treatment affects the outcome.
Potential Outcomes: The hypothetical outcomes that would occur for each individual under different treatment and mediator conditions.
Sequential Ignorability: The assumption that both the treatment and the mediator are effectively randomized, conditional on observed pre-treatment covariates, meaning there are no unobserved confounders.
Sensitivity Analysis: A technique used to assess the robustness of findings to potential violations of key assumptions, such as sequential ignorability, by examining how estimates change as the sensitivity parameters vary.
Single-Experiment Design: A research design where only the treatment variable is randomized, while the mediator is not manipulated.
Treatment Variable: The variable that is manipulated or changed in a study to observe its effect on the outcome variable.
Bailey, Michael A. 2021. Real Stats: Using Econometrics for Political Science and Public Policy. Second edition. New York: Oxford University Press.
Brader, Ted, Nicholas A. Valentino, and Elizabeth Suhay. 2008. “What Triggers Public Opposition to Immigration? Anxiety, Group Cues, and Immigration Threat.”American Journal of Political Science 52 (4): 959–78. https://www.jstor.org/stable/25193860.
Cinelli, Carlos, Jeremy Ferwerda, and Chad Hazlett. n.d. “Sensemakr: Sensitivity Analysis Tools for OLS in R and Stata.”https://doi.org/10.2139/ssrn.3588978.
Cinelli, Carlos, and Chad Hazlett. 2020. “Making Sense of Sensitivity: Extending Omitted Variable Bias.”Journal of the Royal Statistical Society: Series B (Statistical Methodology) 82 (1): 39–67. https://doi.org/10.1111/rssb.12348.
Hazlett, Chad. 2020. “Angry or Weary? How Violence Impacts Attitudes Toward Peace Among Darfurian Refugees.”Journal of Conflict Resolution 64 (5): 844–70. https://doi.org/10.1177/0022002719879217.
Imai, Kosuke, Luke Keele, Dustin Tingley, and Teppei Yamamoto. 2011. “Unpacking the Black Box of Causality: Learning about Causal Mechanisms from Experimental and Observational Studies.”American Political Science Review 105 (4): 765–89. https://doi.org/10.1017/S0003055411000414.
Tingley, Dustin, Teppei Yamamoto, Kentaro Hirose, Luke Keele, and Kosuke Imai. 2014. “Mediation : R Package for Causal Mediation Analysis.”Journal of Statistical Software 59 (5). https://doi.org/10.18637/jss.v059.i05.
For detailed explanation see the Video by Carlos Cinelli here and read the paper Cinelli and Hazlett (2020).↩︎